CutLER
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
利用自监督模型的特性,在无监督的情况下发现对象,并用于训练一个无监督的定位模型。
Motivation
这项工作中,作者研究了无监督的目标检测和实例分割模型,这些模型可以在没有任何人工标记的情况下进行训练。
Key insight: 简单的probing和训练机制可以放大自监督模型的固有定位能力,从而产生最先进的无监督zero-shot detectors。
以往的自监督ViT模型可以无监督检测图像中的单个显著对象,如TokenCut,但这种显著对象检测方法只能定位单个对象,不能用于包含多个对象的真实世界图像。
FreeSOLO和DETReg也旨在进行无监督的多对象检测或多对象发现,但它们依赖于特定的检测架构,且在ImageNet训练过后,还需要在特定域内完成微调,而不能直接应用。
CutLER特点:
- Simplicity:不受主干架构选择影响(不需要特定的检测架构),易于训练
- Zero-shot detector:尽在ImagNet上进行训练,直接在11个不同的benchmark上进行zero-shot推理,甚至优于以往使用了特定域内数据的方法
- Robustness:域适应性很强
- Pretraining for supervised detection:将CutLER作为预训练模型,提升下游全监督任务性能
Methodology
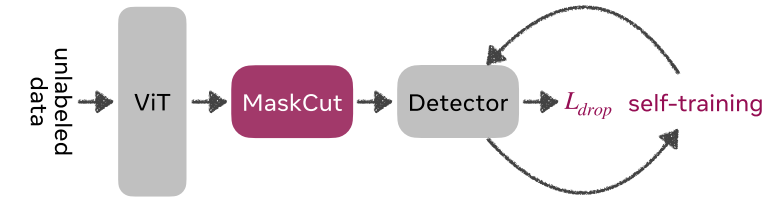
在ImageNet上训练,直接应用到广泛域上进行分割和检测任务。
CutLER由三个simple, architecture- and data-agnostic mechanisms组成:
- MaskCut:利用预先训练好的自监督特征为每幅图像自动生成多个初始粗糙mask
- a simple loss dropping strategy:使用粗糙的mask训练detectors,同时保持模型对MaskCut遗漏的对象的鲁棒性
- self-training:作者证明了对模型自身预测的多轮自训练允许它从捕获局部像素的相似性演变为捕获对象的全局几何形状,从而产生更精细的分割模板。
TokenCut的一个局限性是它只为一个图像计算一个二进制掩码,因此每个图像只能找到一个对象。虽然我们可以使用其他N-2个最小的特征向量来定位多个实例,但这会显著降低多对象发现的性能。
MaskCut for Discovering Multiple Objects
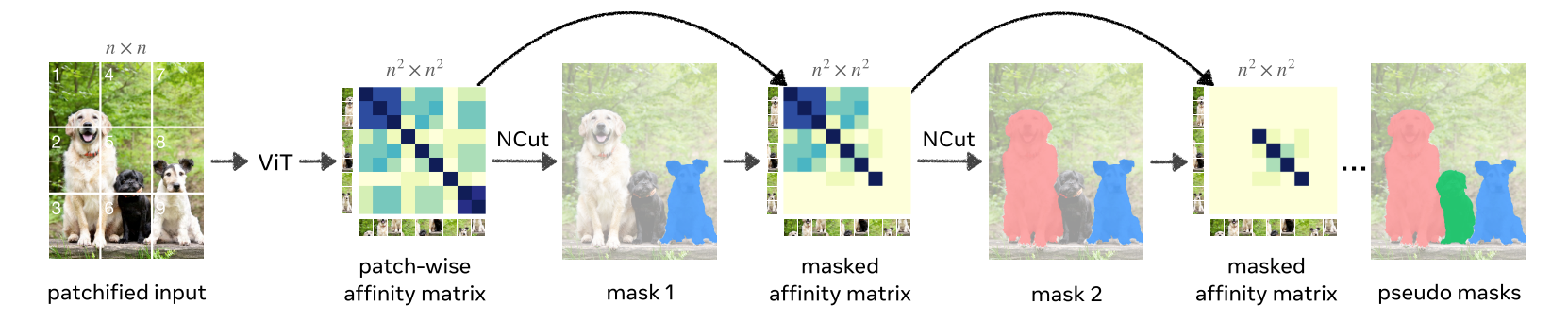
作者在DINO和TokenCut的基础上建立MaskCut,并使用自监督DINO 模型的特征为图像创建逐块相似性矩阵,并将Normalized Cuts 应用于该矩阵,并获得图像的单个前景对象掩模。然后,使用前景mask屏蔽亲和度矩阵值并重复该过程,这允许MaskCut在单个图像中发现多个对象mask。在此pipeline示意图中,作者设置n = 3,也就是将图像切分为$3\times 3$个块。
TokenCut中提到,第二小特征值对应的特征向量提供了切割结果,因为它的绝对值表示token属于前景对象的可能性。
在每次对部分遮掩的相似度矩阵应用NCut后,使用第二小特征值对应的特征向量的均值将图划分为两个子图,对于第t阶段,获得一个二值掩码$M^t$。
判断两个子图哪个属于前景哪个属于背景,作者使用了两个先验:
- 直观来说,前景应该比背景更突出,因此前景mask应该包含第二小特征向量中最大绝对值对应的块。
- 前景集合应当包含少于四个角中的两个角。
每个阶段都会获得一个对象的掩码,为了获得第$(t+1)^{th}$对象,作者通过将前面所有阶段所得到的前景对象相关的节点从节点相似度矩阵中mask out的方式更新相似度矩阵,默认t=3,也就是找3个前景对象。
DropLoss for Exploring Image Regions
由于MaskCut产生的伪标签可能会遗漏实例目标,标准的loss function没办法使detector发现’ground-truth’中没有的新实例,因此作者认为应该忽略与’ground-truth’也就是MaskCut产生的伪标签只有较小重叠的预测区域。具体来说,就是计算预测的区域和所有伪标签对象区域的IoU,当IoU小于提前设定的阈值$\tau^{IoU}$时,不计算这一预测区域产生的loss。也就是实现了鼓励模型发现新实例的目的。
Multi-Round Self-Training
作者通过实验发现,尽管模型是从MaskCut产生的粗糙掩码中学习,但是模型能够’clean’伪标签,产生比初始用于训练的粗略mask更好的masks和boxes。因此作者提出利用DropLoss和这一自我’clean’的特性进行多轮的self-training来提高检测器的性能。
作者使用来自第t轮的置信度大于0.75 - 0.5t的预测masks和proposals作为第(t + 1)轮自训练的附加伪注释。为了降低重复的伪标签数量,作者另外去掉了与预测区域具有大于等于0.5IoU的伪标签(保留新的,去掉旧的)。作者通过实验发现,3轮自训练足够使模型有较好的效果。
Implementation Details
- 仅使用ImageNet进行训练,且不使用任何标注
- MaskCut在得到粗略掩码后使用CRF进行后处理,然后获取边界框
- CutLER中的检测器可以是任意的,但是作者默认使用Cascade Mask R-CNN
Experiments
作者评估了CutLER作为用于训练对象检测和实例分割模型的预训练方法。虽然CutLER可以在没有任何监督的情况下发现对象,但在目标数据集上对其进行微调会将模型输出与数据集中标记的同一组对象对齐。