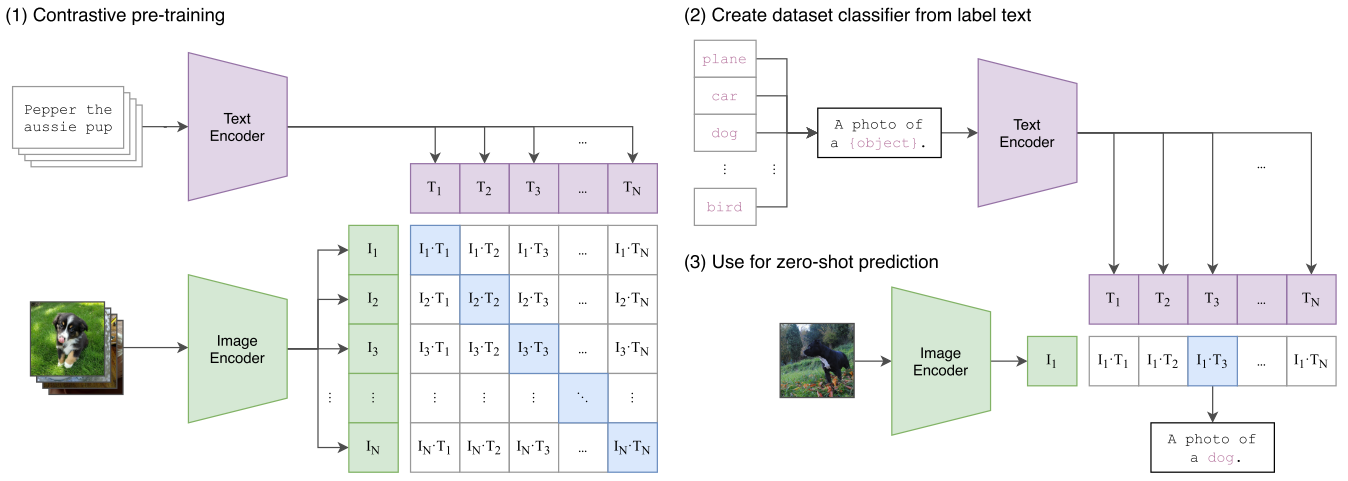
CLIP
Learning Transferable Visual Models From Natural Language Supervision
基于对比学习在超大规模的图像文本对数据集上进行训练,具有很强的zero-shot推理能力
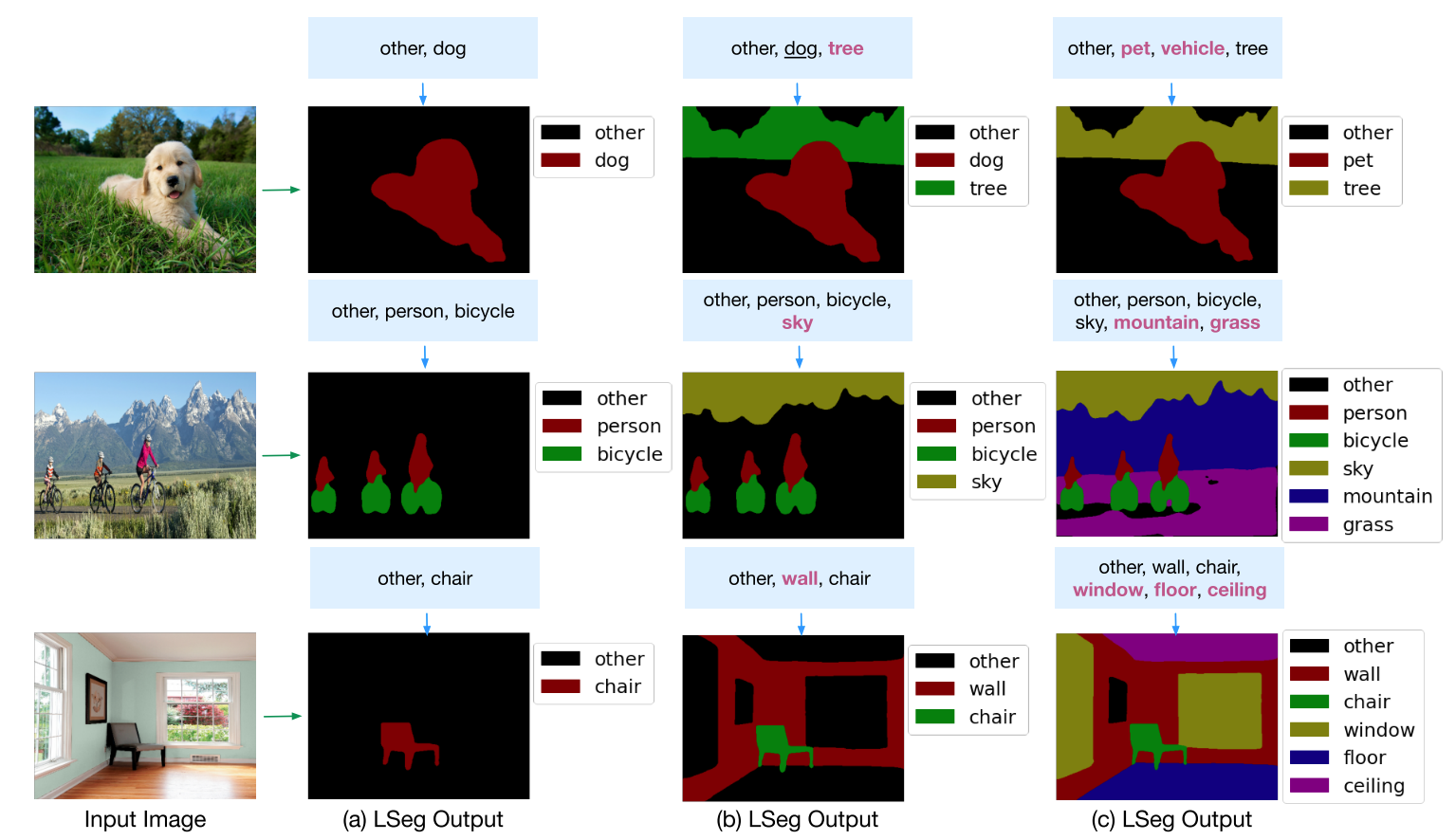
LSeg
Language-driven semantic segmentation
使用文本信号来做zero-shot的分割,训练过程中是有监督的(在7个分割数据集上训练),文本编码器部分直接使用了CLIP的文本编码器,训练阶段也是冻结的。
language-guided分割,可以应用于图像PS等
Methodology
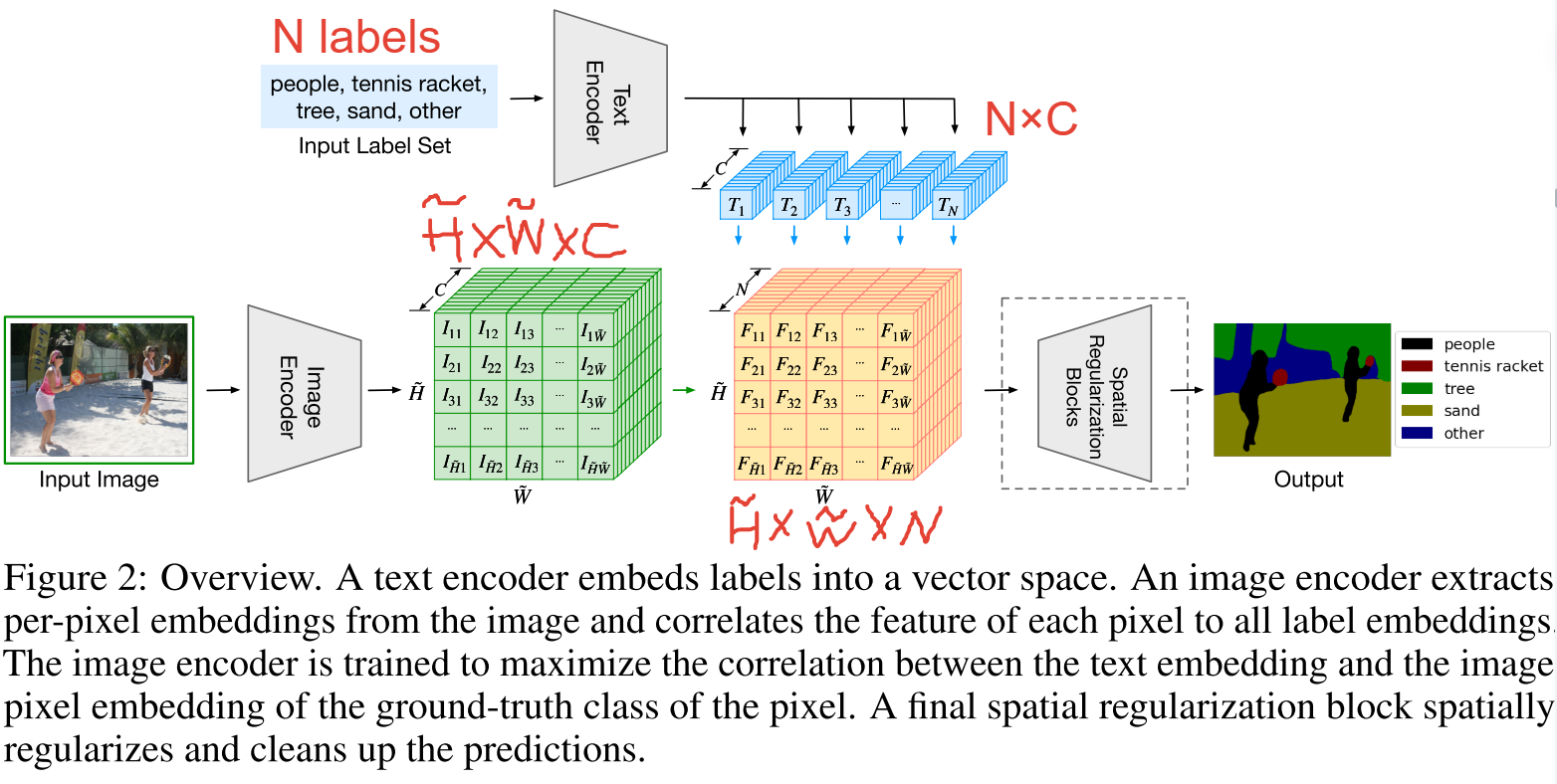
- 视觉分支:本方法和有监督的语义分割方法一样,输入图像,提取特征(bottleneck feature),然后upscaling至与原图一样大小,模型输出与ground truth mask做cross entropy loss。图中的$\tilde{H},\tilde{W}$代表降维后的bottleneck feature的高宽。注意训练时是有监督的(7个分割数据集)。
- 文本分支:输入N个labels(N是随时可以变化的),经过文本编码器得到N个C维的文本特征。为了保证文本编码器的效果,本文直接采用了CLIP的文本编码器,在训练时也是冻结的。
- 交互:$\tilde{H}\times \tilde{W}\times C$的图像密集特征与$N\times C$的文本特征在$C$这一维度相乘,输出为$\tilde{H}\times \tilde{W}\times N$的特征图,N就是类别数量,经upscaling和可学习的模块调整后与ground truth mask做cross entropy loss。
Experiment
Datasets
在few-shot segmentation benchmark上进行评估
Contribution & Limitation
Contribution:
- 把文本分支引入传统的有监督分割模型中,学习到language-aware的视觉特征,因此在推理时可以使用文本prompt做zero-shot segmentation
Limitation:
- 虽然使用了CLIP的预训练模型,但并不是将文本作为监督信号,目标函数仍旧是有监督中的cross entropy,依赖于手工标注的segmentation mask
CVPR2022 GroupViT
GroupViT: Semantic Segmentation Emerges from Text Supervision
利用文本信号作为监督,摆脱了对segmentation mask的依赖,从而实现无监督的训练
Metodology
在已有的ViT框架中加入grouping block和可学习的group tokens
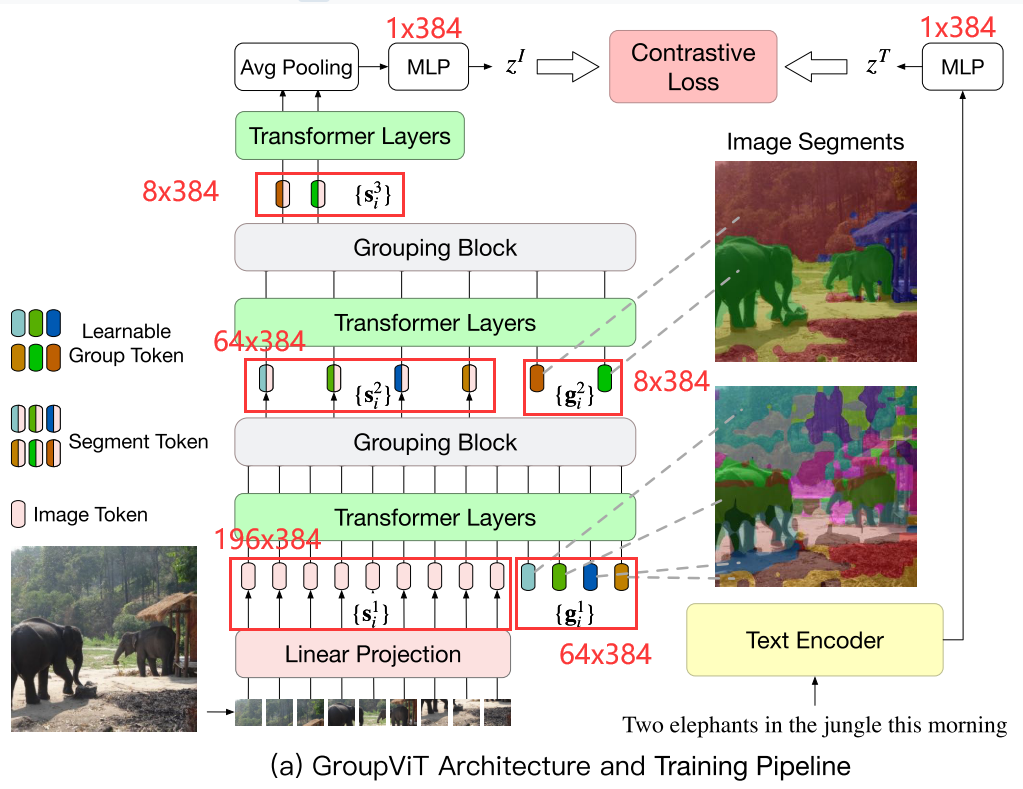
Framework:
- 图像编码器的输入包括两个部分:1)原始图像的Patch Embedding,即图中$\{s_i^1\}$,2)Group Token,即图中$\{g_i^1\}$(每一个代表一块区域)
如果图像尺寸为$224\times 224$,patch size为$16\times 16$, 得到$14\times14=196$长度的序列,经过Linear Projection得到Patch Embedding,如使用ViT-small则Patch Embedding特征维度为384,所以来自图像的输入变为$196\times 384$
作者假设了group tokens的初始数量为64,即来自这一部分的输入为$64\times384$, 设置为64是为了在一开始有尽量多的聚类中心,group tokens与ViT中的cls token类似,cls token是想用一个token来代表整个图像,而64个group tokens是想代表一张图像的64个类/块,将语义接近的相似像素归结到64个clusters中
- 将Group Token和Image Token组成的输入经6层Transformer Layers后送到到Grouping Block,将每个patch分配到对应的group中去,得到64个Group 的特征,也就是图中的$\{s_i^2\}$(Segment Token),维度为$64\times384$,至此将一个输入为$(196+64)\times 384$的输入降维至$64\times384$, 完成了第一次分配。
- 为了进一步合并group,作者在第一层Grouping Block之后又加入了8个可学习的Group Token$\{g_i^2\}$,然后经过3层Transformer Layers后再次送入Grouping Block进行第二次分配,得到8个group的特征
- 由于最后的目标函数是图像文本配对的对比损失函数,因此需要得到一个表示图像整体的特征,作者这里简单的将8个group的特征进行平均,得到一个$1\times 384$的特征,与文本编码器获得的特征进行对比学习loss的计算。
Grouping Block
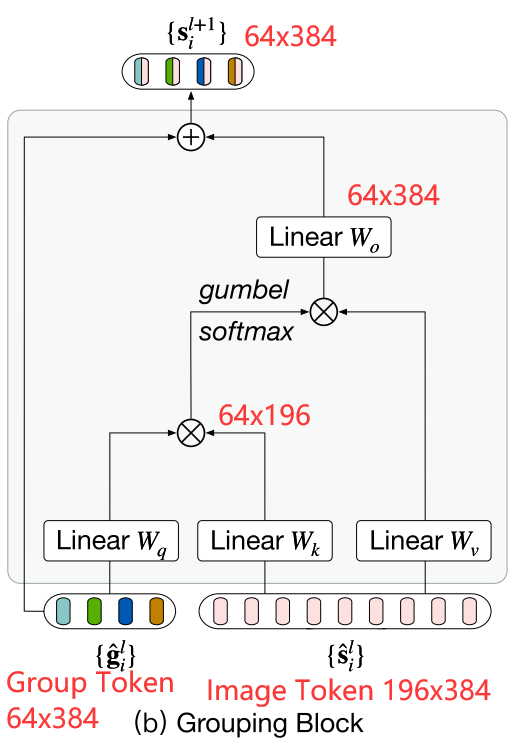
在Grouping Block内部:
首先使用了类似于自注意力机制的方式,将Group Token作为q,Segment(Image) Token作为k,计算出相似度矩阵,维度为$64\times 196$,每一列代表当前Image Token和64个Group Token的相似度
然后对group tokens维求argmax,也就是在一列上求argmax,实际用gumbel_softmax 来替代argmax(图中得到的矩阵维度仍然是$64\times 196$,但变为了196个one-hot列向量),也就是计算每个Segment(Image) Token应该被分配给哪个Group Token。
经gumbel_softmax 得到的分配矩阵与Segment(Image) Token特征矩阵相乘,得到更新的Group Token特征$64\times 384$
假设现在有2个Group Token,则相似度矩阵经过gumbel_softmax(对Group Token维)后,每列近似为一个one-hot向量,如$\begin{bmatrix}
0& 1& 0\\
1& 0& 1
\end{bmatrix}$,作用是将Segment(Image) Token分配给Group Token,这里先暂时称为分配矩阵。若存在3个Segment(Image) Token,且特征维度为4,设为$\begin{bmatrix}
a& b& c& d\\
e& f& g& h\\
i& j& k& l
\end{bmatrix}$,与分配矩阵相乘,得到一个$2\times4$的矩阵,也就是更新得到了2个Group Token的特征,不难看出,每个Group Token的特征就是属于这一Group Token的所有Segment(Image) Token的特征之和(在每一维相加),并未进行平均的操作(做了是否会更好?)$\begin{bmatrix}
0& 1& 0\\
1& 0& 1
\end{bmatrix}
\begin{bmatrix}
a& b& c& d\\
e& f& g& h\\
i& j& k& l
\end{bmatrix}=\begin{bmatrix}
e& f& g& h\\
a+i& b+j& c+k& d+l
\end{bmatrix}$
gumbel_softmax trick替代argmax解决了argmax操作不可导的问题, gumbel-softmax里面的 $\tau$值越接近无穷获得的向量越接近一个均匀分布的向量;$\tau$值越接近0获得的向量越接近一个one-hard vector;$\tau$值越接近1则gumbel-softmax就和softmax越类似
Multi-label Image-Text Contrastive Loss
给定一个输入图像-文本对,通过提取其名词并使用多个句子模板提示它们来从原始文本生成新文本。训练GroupViT和文本编码器使正图像-文本对之间的特征相似度最大化,负图像-文本对之间的特征相似度最小化。
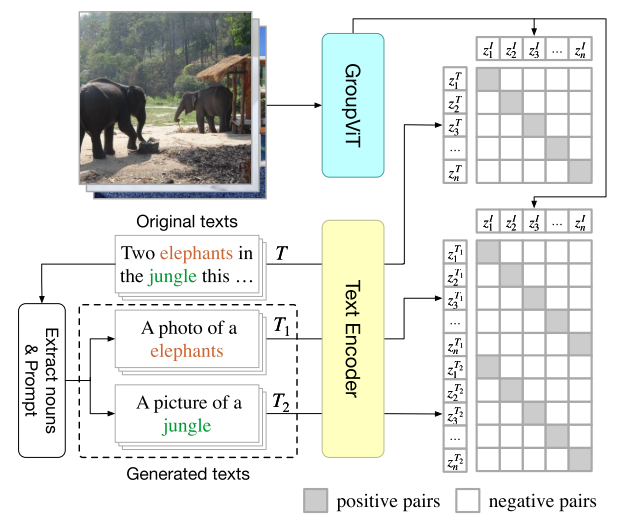
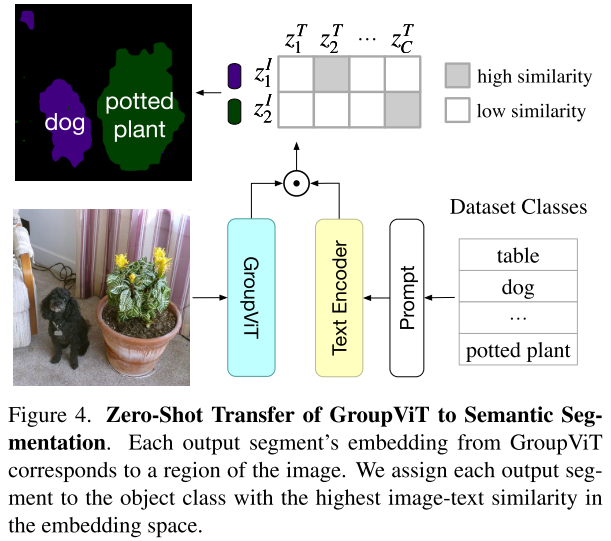
Zero-Shot Inference
图片送入GroupViT后,得到8个segments的特征,然后将label送入文本编码器,得到label对应的文本特征,然后计算segment embedding和文本特征的相似度,选择最大相似度的label作为输出。背景类是使用阈值0.9来得到。
存在局限性:由于固定了8个group,因此最多分出8个类
Limitation & Future Work
- 并未使用一个更适合分割的backbone
- 背景类干扰问题显著,分割分的不错,但是由于分类错误使得最后的mIoU较低,如果分类都正确则分割性能就逼近有监督性能了。这一问题主要是由于CLIP的训练方式,背景类是个模糊的概念,没有明确的物体语义信息。
- 可学习的背景阈值
- 训练时加入约束,引入背景概念
- 修改zero-shot推理的方式
CVPR2022 CLIMS
Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Motivation
CAM通常仅激活判别性对象区域,并且错误地包含许多与对象相关的背景。WSSS模型仅可用一组固定的image-level对象标签进行训练,因此很难抑制由开放集对象(open set objects)组成的不同的背景区域。
WSSS往往由3个阶段:
- 训练并产生CAM
- 细化CAM,生成伪标签
- 使用伪标签训练一个分割网络
由于在close-world setting中,和目标密切相关的背景有助于目标对象的分类,比如背景铁轨和目标对象火车,这会导致CAM不必要的激活背景,此外,CAM还会struggles in the underestimation of object contents。这限制了初始CAM的质量。
CLIM框架的核心思想是引入自然语言监督来激活更完整的对象区域并抑制密切相关的开放背景区域
Methodology
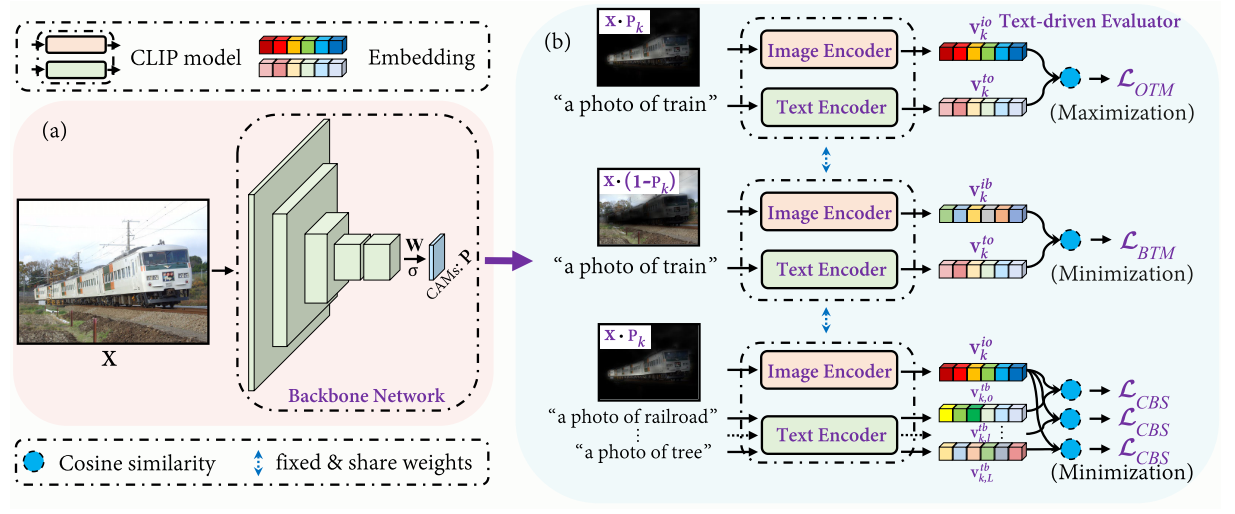
Framework
Backbone Network
CLIM在CAM的基础上,去掉了GAP,并使用sigmoid进行了归一化,得到k个类别的激活图(CAMs) $\mathbf{P}$:
$\mathbf{P}_{k}(h, w)=\sigma\left(\mathbf{W}_{k}^{\top} \mathbf{Z}(h, w)\right)$
W指全连接层,Z是最后一层卷积输出的特征图。
Text-driven Evaluator
Text-driven Evaluator使用了CLIP model,包含图像编码器$f_{i}(\cdot)$和文本编码器$f_{t}(\cdot)$。
首先利用$\mathbf{P}$和$1-\mathbf{P}$来屏蔽背景和前景,并送入图像编码器,获得每个类别的图像特征表示,o代表object,b代表background:
$\mathbf{v}_{k}^{i o}=f_{i}\left(\mathbf{X} \cdot \mathbf{P}_{k}\right), \quad \mathbf{v}_{k}^{i b}=f_{i}\left(\mathbf{X} \cdot\left(1-\mathbf{P}_{k}\right)\right)$
与CLIP一样,CLIMs也使用了text prompt(文本提示) “a photo of {}”, 在分类的标签基础上,CLIMs还另外预先定义了k个类别密切相关(常常同时出现)的背景类别co-occurring background closely related with the object,并将text prompt后的句子送入文本编码器,获得每个类别的文本特征表示:
$\mathbf{v}_{k}^{t o}=f_{t}\left(\mathbf{t}_{k}^{o}\right), \quad \mathbf{v}_{k, l}^{t b}=f_{t}\left(\mathbf{t}_{k, l}^{b}\right)$
$\mathbf{t}_{k}^{o}$和$\mathbf{t}_{k, l}^{b}$分别表示对象的文本标签和特定类k的第l类相关共出现背景。
1 | background_dict = { |
Object region and Text label Matching
对于前景对象,使图像特征表示和文本特征表示相似度最大化
$\mathcal{L}_{O T M}=-\sum_{k=1}^{K} y_{k} \cdot \log \left(s_{k}^{O O}\right)$
$s_{k}^{o o}=\operatorname{sim}\left(\mathbf{v}_{k}^{i o}, \mathbf{v}_{k}^{t o}\right)$
Background region and Text label Matching
为了提升前景对象激活的完整性,提出了the background region and text label matching loss来寻找更完整的object contents, 使背景的图像特征表示和前景的文本特征表示相似度最小化:
$\mathcal{L}_{B T M}=-\sum_{k=1}^{K} y_{k} \cdot \log \left(1-s_{k}^{b o}\right)$
$s_{k}^{b o}=\operatorname{sim}\left(\mathbf{v}_{k}^{i b}, \mathbf{v}_{k}^{t o}\right)$
当这一损失变小时,意味着在$\mathbf{X} \cdot\left(1-\mathbf{P}_{k}\right)$中保留了更少的目标对象像素,在$\left(\mathbf{X} \cdot \mathbf{P}_{k}\right)$中恢复了更多的目标对象内容。
Co-occurring Background Suppression
上述两个损失函数仅确保P完全覆盖目标对象,而没有考虑共同发生的类相关背景的错误激活。
因此,CBS则是使前景对象的图像特征表示和背景的文本特征表示的相似度最小化。
$\mathcal{L}_{C B S}=-\sum_{k=1}^{K} \sum_{l=1}^{L} y_{k} \cdot \log \left(1-s_{k, l}^{o b}\right)$
$s_{k, l}^{o b}=\operatorname{sim}\left(\mathbf{v}_{k}^{i o}, \mathbf{v}_{k, l}^{t b}\right)$
Area Regularization
在只有$\mathcal{L}_{O T M}, \mathcal{L}_{B T M} $,和$ \mathcal{L}_{C B S}$时,如果激活映射中同时包含了不相关的背景和目标对象,CLIP仍然可以正确预测目标对象。因此,作者还提出了一个像素级区域正则化项来约束激活图的大小,以确保在激活图中排除不相关的背景:
$\mathcal{L}_{R E G}=\frac{1}{K} \sum_{k=1}^{K} S_{k}, \quad \text { where } \quad S_{k}=\frac{1}{H W} \sum_{h=1}^{H} \sum_{w=1}^{W} \mathbf{P}_{k}(h, w)$
Overall
$\mathcal{L}=\alpha \mathcal{L}_{O T M}+\beta \mathcal{L}_{B T M}+\gamma \mathcal{L}_{C B S}+\delta \mathcal{L}_{R E G}$
用4个超参来调整各loss的权重
Contributions
- 通过直接使用CLIP来引入文本监督
- 利用CLIP来对open-world setting下WSSS方法中错误激活的背景进行抑制