ICML2021 ViLT
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Background & Motivation
作者将Vision-and-Language Pretraining(VLP)模型分为了4种类型,如下图所示。每个矩形的高表示相对计算量大小,VE、TE和MI分别是visual embedding、text embedding和modality interaction的简写。
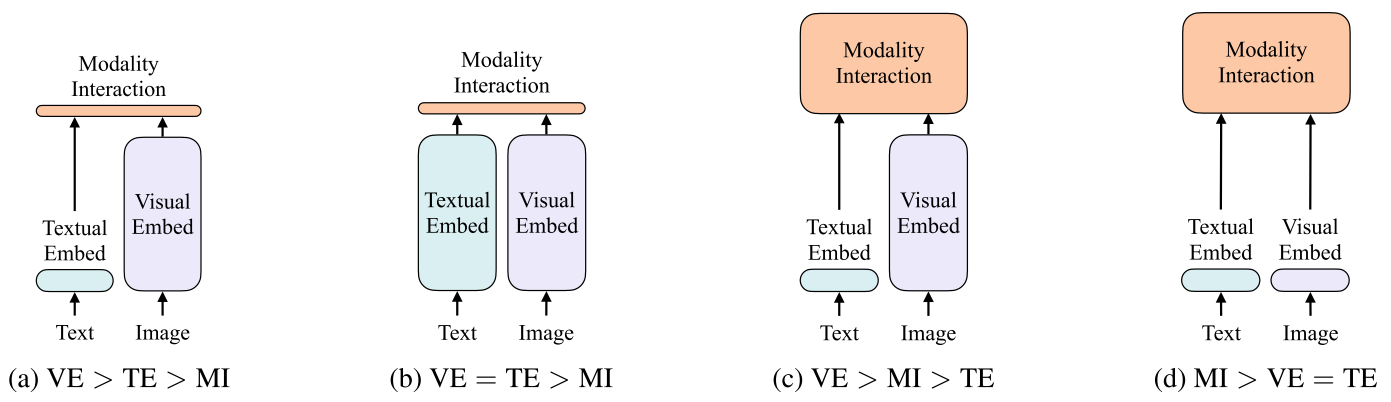
作者这样分类的依据为:
- embedding阶段视觉部分和文本部分的参数量,计算量是否平衡
- 交互阶段是否有深层的transformer进行交互(如a,b类的交互一般为简单的点积或者浅层的attention层来计算相似性,c,d类交互阶段的计算量更大,本文就属于d)
作者认为以往的VLP模型至少存在两个问题:
- 效率低,特征抽取阶段占据了比特征交互大得多的计算量
- 表达能力受限,因为使用预训练的视觉模型来抽取特征,视觉预训练模型本身只是由固定的数据集训练得到,而且这一过程不能实现端到端
以往的VLP算法耗时主要都集中在Visual embedding的部分,ViLT是首个将VE设计的如TE一样轻量的方法,该方法的主要计算量都集中在模态交互上。
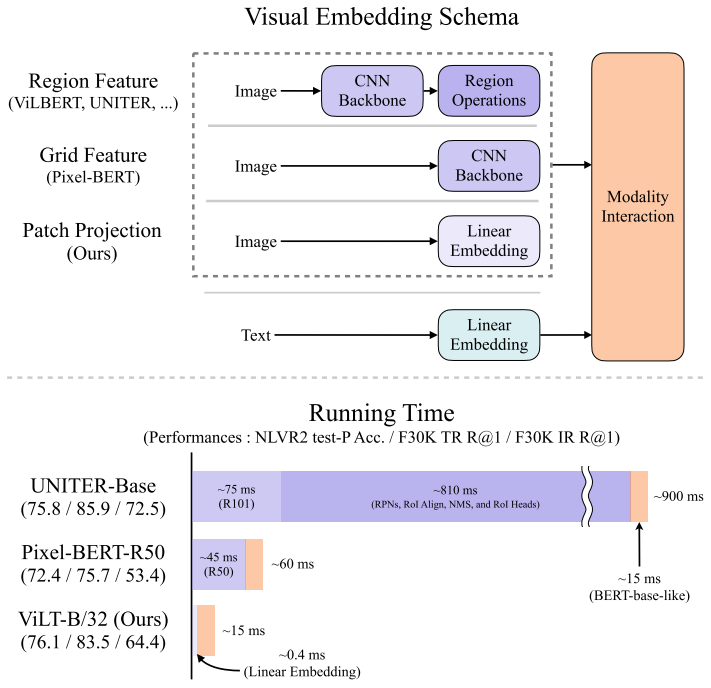
Visual Embedding Schema
现有的VLP模型的text embedding基本上都使用类BERT结构,但是visual embedding存在着差异。在大多数情况下,visual embedding是现有VLP模型的瓶颈。visual embedding的方法总共有三大类,其中region feature方法通常采用Faster R-CNN二阶段检测器提取region的特征,grid feature方法直接使用CNN提取grid的特征,patch projection方法将输入图片切片投影提取特征。ViLT是首个使用patch projection来做visual embedding的方法。
将目标检测系统嵌入到多模态学习中,大致分为3步:
- Backbone,抽取特征
- NMS:利用一个RPN网络抽取RoI,然后对RoI做NMS,把RoI降到固定的数量,也就是视觉的特征序列长度
- RoI head:把上一步得到的bounding box通过一个RoI head来抽取出一维的特征向量,也就是region feature
Modality Interaction Schema
模态交互部分可以分成两种方式:一种是single-stream(如BERT和UNITER),另一种是dual-stream(如ViLBERT和LXMERT)。其中single-stream是对图像和文本concate然后进行交互操作,而dual-stream是不对图像和文本concate,分别送进视觉的transformer和NLP的模型,然后在某个时间点进行交互操作。ViLT延用single-stream的交互方式,因为dual-stream会引入额外的计算量。
Methodology
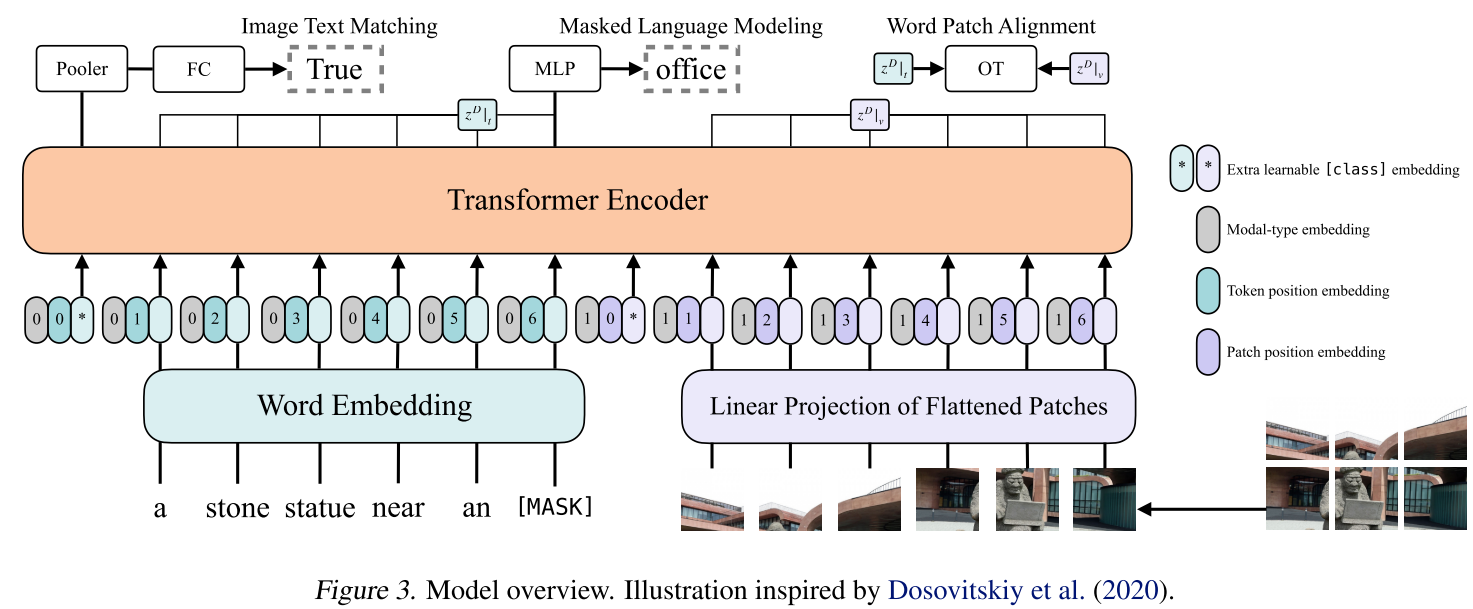
输入:
- 输入的句子经过bert tokenizer编码得到$L\times H$的Word Embedding,其中$L$是文本序列长度, $H$为token embedding的维度(base:768)
- 输入的图像经过编码得到$N$个patch tokens,维度与文本的token embedding维度一样为$H$
- 将文本的L个token embedding、指示模态类型的modal-type embedding和位置编码相加(注意图中贴在一起,但不是拼接,是直接相加),然后将相加后的L个tokens embedding进行concat
- 图像的的N个patch tokens embedding也做一样的操作,并在wrod embedding和visual embedding分别都嵌入了一个额外的可学习[class] embedding,方便和下游任务对接,最终得到transformer的输入,输入序列为$(N+L+2)\times H$,
训练优化目标Pretraining Objectives:
ViLT预训练的优化目标有两个:一个是image text matching(ITM),另一个是masked language modeling(MLM)。
ImageText Matching:随机以0.5的概率将文本对应的图片替换成不同的图片,然后使用一个线性的ITM head(图中的Pooler和FC,Pooler是一个$H \times H$的矩阵)将输出的cls token feature($1\times H$)映射成一个二值logits(也就是$1\times H$乘上$H\times H$的Pooler,得到$1\times H$的输出,送到FC,最终得到logits),做二分类,判断图像文本是否匹配。另外ViLT还设计了一个word patch alignment (WPA)来计算textual subset和visual subset的对齐分数, 利用了optimal transport最优运输理论,可以直观理解为,将文本部分输出和图像部分输出视作是两个分布,WPA则是计算两个分布之间的距离,优化的目标就是让这个距离越小越好。
Masked Language Modeling:MLM的目标是通过文本的上下文信息去预测masked的文本tokens。随机以0.15的概率mask掉tokens,然后文本输出接两层MLP来预测mask掉的tokens。
Whole Word Masking:另外ViLT还使用了whole word masking技巧。whole word masking是将连续的子词tokens进行mask的技巧,避免了只通过单词上下文进行预测。比如将“giraffe”词tokenized成3个部分[“gi”, “##raf”, “##fe”],可以mask成[“gi”, “[MASK]”, “##fe”],模型会通过mask的上下文信息[“gi”,“##fe”]来预测mask的“##raf”,就会导致不利用图像信息。
Image Augmentation: 以往的工作如基于目标检测的多模态学习方法没办法使用数据增强方法,因为这些方法在训练时是提前抽取好特征,存储在硬盘上,并非端到端的,如果需要做数据增强,就需要重新抽取特征,训练会变得非常麻烦。ViLT是端到端的,引入了RandAugment数据增强方法,但是去掉了color jitter和cutout。
Experiments
Datasets
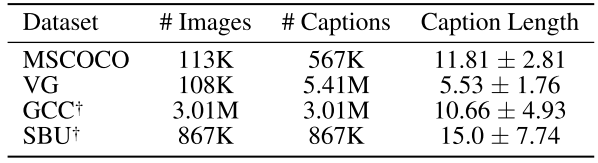
预训练是在4 million setting下进行的:
Contributions & Weakness
Contributions:
- 简单性:ViLT是首个将VE设计的如TE一样轻量的方法,去掉了CNN抽取特征和目标检测的步骤,推理速度更快。
- 探索了更多的数据增强方式应用于多模态学习,提升精度
Weakness:
- 精度一般
- 训练成本昂贵