ECCV2020 DETR
End-to-End Object Detection with Transformers
Motivation
现阶段的目标检测器都是使用间接的方式处理集合预测问题,没有直接做集合预测任务,而是定义回归或者分类问题来替代,以间接方式解决集合预测任务。这些方法性能受限于后处理操作,如NMS。
- proposals: R-CNN系列工作
- anchors: Yolo系列工作
- non-anchor based(window centers): CenterNet,FCOS
DETR去掉了需要人工设计的组件,如NMS和先验anchor,因此DETR框架是非常简洁的,使目标检测变得简单。
Methodology
Object detection set prediction loss
DETR提出了一种集合预测损失,该损失强制预测框和GT框之间进行唯一匹配(因此可以不需要NMS,可以一对一出框)
DETR的输出是一个固定的集合,最后都会输出N=100个框,但是由于一张图像只有几个GT框,计算loss需要知道预测框应该与哪个GT框进行匹配。作者将这一问题转换成了一个最优二分图匹配问题optimal bipartite matching。
scipy中提供了linear-sum-assignment(匈牙利算法),输入cost matrix,就可以输出最优匹配结果。
cost matrix可以理解为将a,b,c三个工人分配去做x,y,z三个工作,分别的耗时(代价),然后选取一个最优的分配方式,在DETR中,abc是100个预测的框,xyz是GT框,遍历所有的预测框和GT框,然后利用分类损失和定位损失来计算得到cost matrix,然后再利用匈牙利算法获得最优匹配。
$\hat{\sigma}=\underset{\sigma \in \mathfrak{S}_{N}}{\arg \min } \sum_{i}^{N} \mathcal{L}_{\operatorname{match}}\left(y_{i}, \hat{y}_{\sigma(i)}\right)$
$\mathcal{L}_{\text {match }}\left(y_{i}, \hat{y}_{\sigma(i)}\right)=-\mathbb{1}_{\left\{c_{i} \neq \varnothing\right\}} \hat{p}_{\sigma(i)}\left(c_{i}\right)+\mathbb{1}_{\left\{c_{i} \neq \varnothing\right\}} \mathcal{L}_{\text {box }}\left(b_{i}, \hat{b}_{\sigma(i)}\right)$
有了最优匹配的结果,意味着计算损失时预测框和GT框是一对一的,而不是多对一的
$\mathcal{L}_{\text {Hungarian }}(y, \hat{y})=\sum_{i=1}^{N}\left[-\log \hat{p}_{\hat{\sigma}(i)}\left(c_{i}\right)+\mathbb{1}_{\left\{c_{i} \neq \varnothing\right\}} \mathcal{L}_{\mathrm{box}}\left(b_{i}, \hat{b}_{\hat{\sigma}}(i)\right)\right]$
Bounding box loss中作者采用了L1 loss和iou loss的结合,因为DETR经常出大框,L1 loss会随框的大小变化,框越大,loss越大,不利于优化,因此引入了与框大小无关的iou loss。
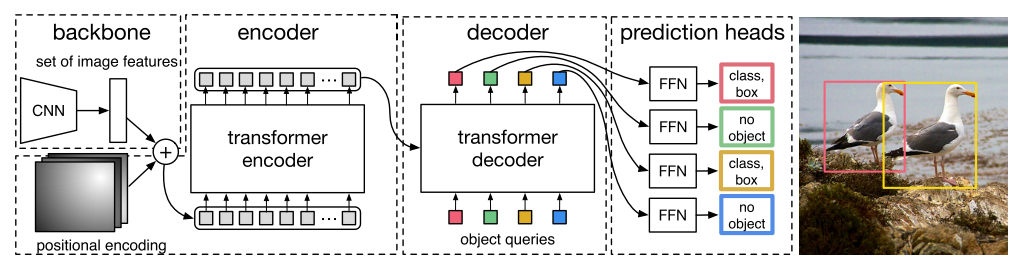
DETR architecture
object queries本质上是learnabel positional embedding,设置为$100\times 256$的向量
decoder做了cross attention,输入是encoder端得到的$850\times256$的全局特征(850个patch),以及object queries。最后输出的也是$100\times 256$,得到这一特征后,送入检测头,进行预测类别和边界框xywh。
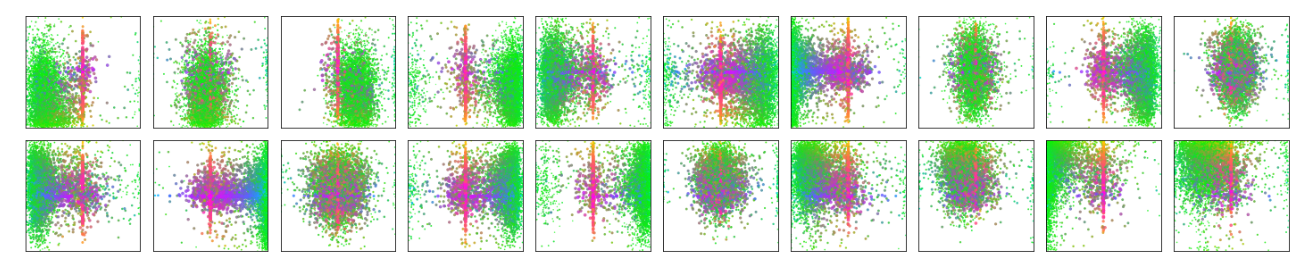
object queries的作用类似于anchor,下图是100个object queries中的20个object queries所预测的box prediction的可视化结果,每个点代表的是box的中心坐标,颜色则是对应小(绿色),中(蓝色),大(红色)三种尺寸。
Contribution&Weakness
Contribution:
新的目标函数
Transformer encoder-decoder结构
weakness:
训练较慢
小目标检测效果不佳
Deformable DETR,解决了小目标和训练慢的问题