Few-Shot Learning
support set不足以训练神经网络,只是在做预测的时候提供一些额外信息。使用大的数据集来训练一个模型,训练目的是让模型知道事物的异同
小样本学习也是一种meta learning,learning to learn
与监督学习的区别:
传统的监督学习的测试样本来自于已知类别,few-shot learning的测试样本来自未知的类别
k-way n-shot:
- k-way:support set有k个类别
- n-shot:每个类别有n个样本,one-shot就是只有一张图片
与比赛不同,few shot learning中,设定query是属于surrport set的,而比赛中是需要判断是不是已知类的
siamese网络的训练:
- 使用正负对进行训练,正对(同一类别)的两个样本的相似度标记为1,负对为0.将样本对输入到同一个网络,提取特征,对特征求差值,得到的特征向量表示两个图片得到的特征向量的区别,然后再送进全连接层,得到一个标量,加上sigmoid进行归一化,得到一个表示similarity的预测值,使用预测值sim和标签(正对为1,负对为0)做crossentropy
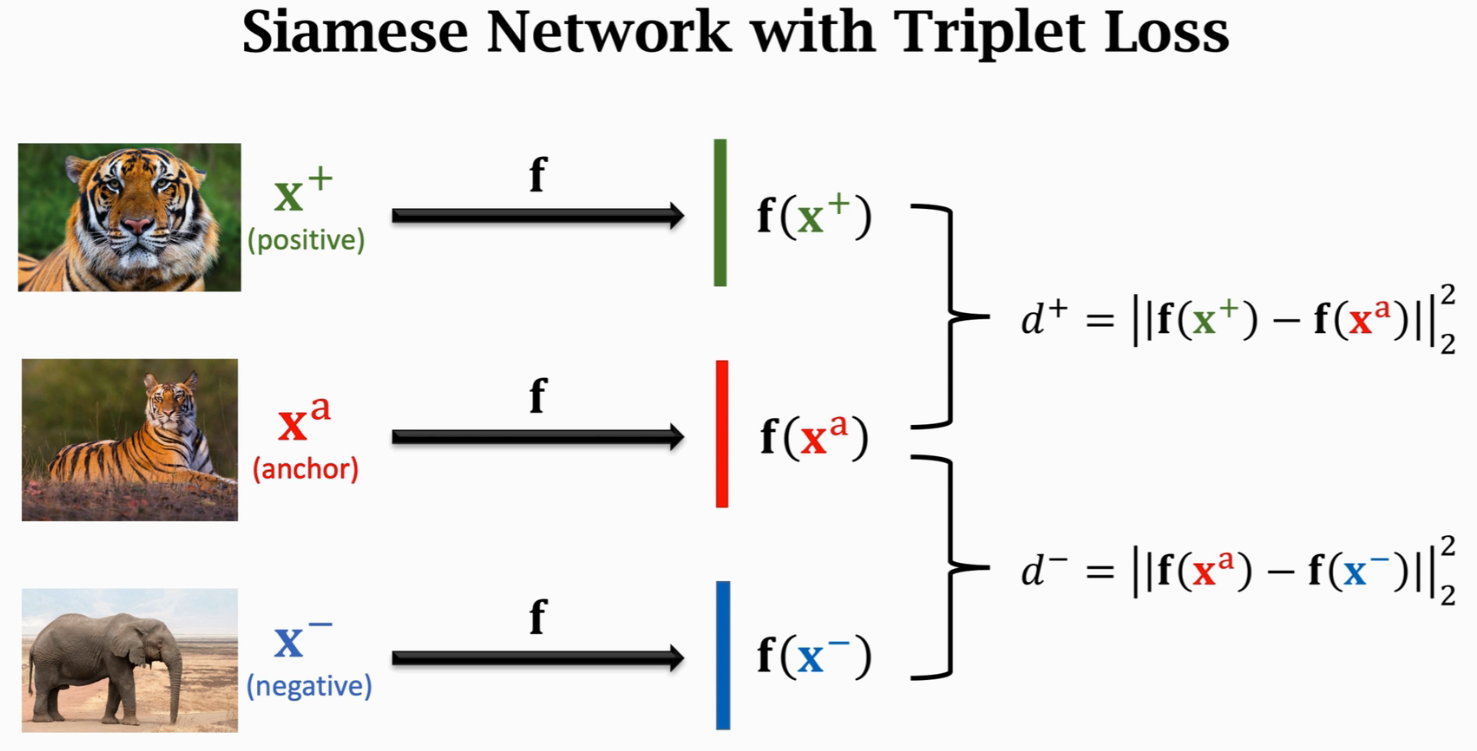
- 使用triplet loss,训练时每次选取3个样本,一个anchor,一个positive,一个negative,让anchor和positive在特征空间的距离更近,anchor和negative在特征空间的距离更远

Cosine Similarity
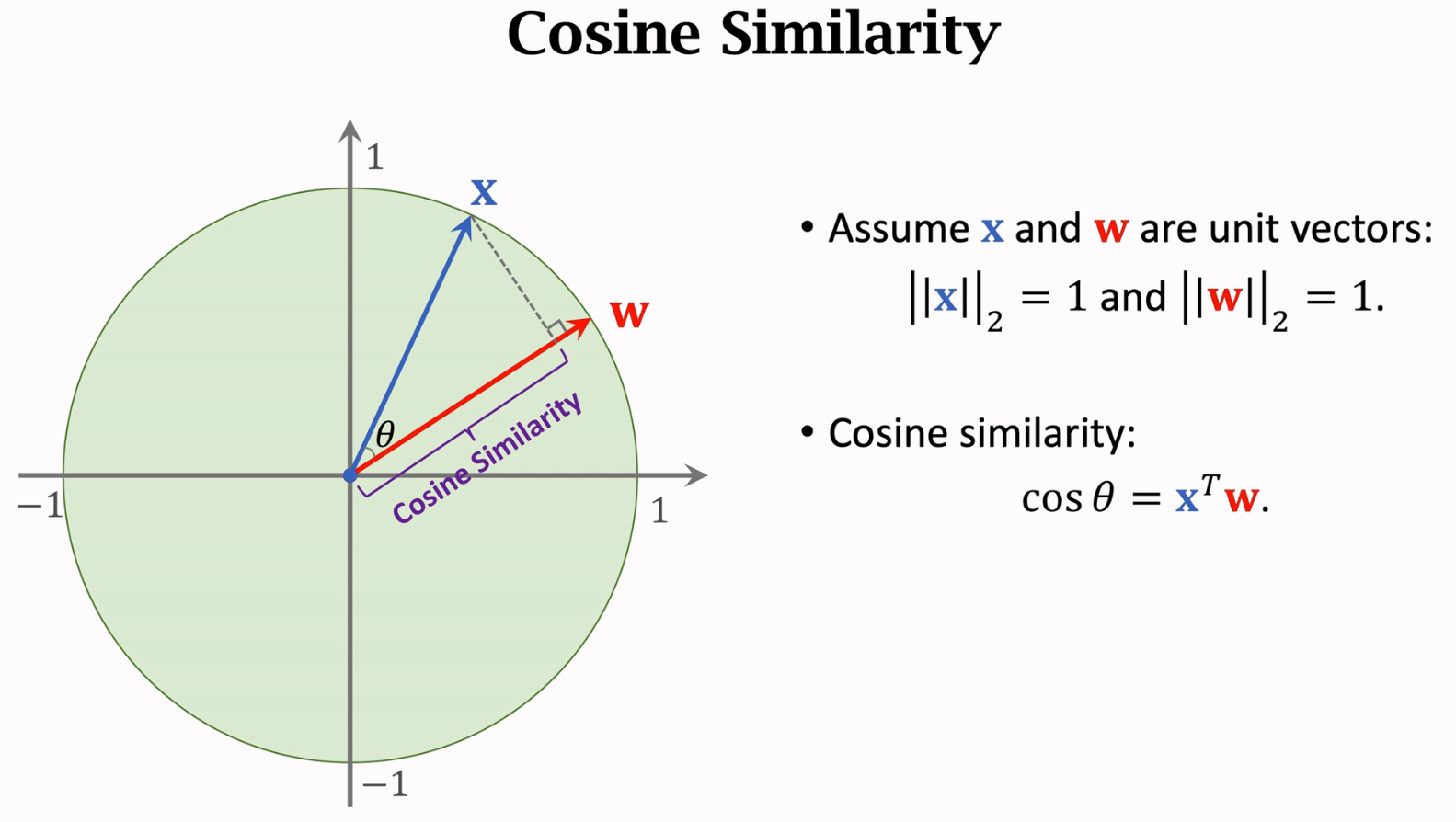
当x和w的向量长度都是1时,cos就等于x和w的内积
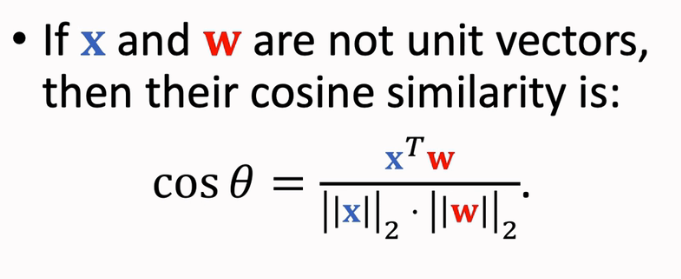
softmax

对向量取指数,然后normalize(归一化)
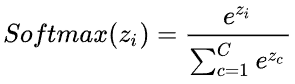
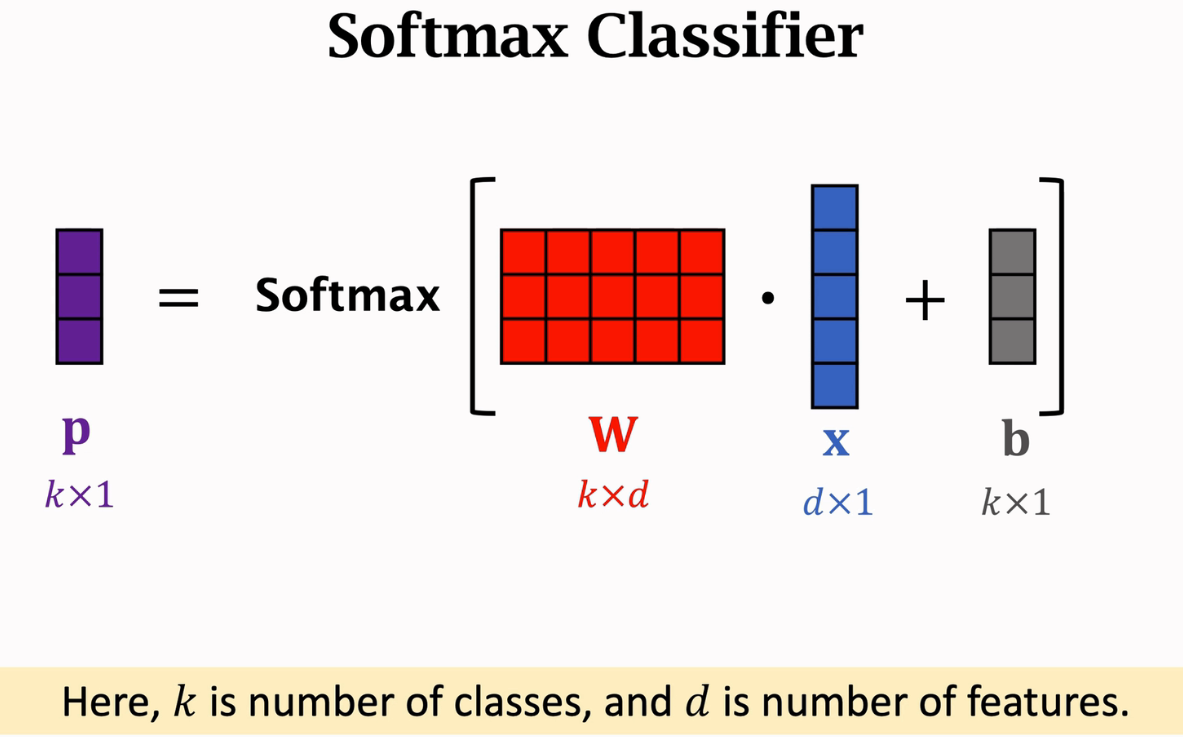
softmax分类器,实际上是全连接层加softmax函数,x是输入的特征向量,w是全连接层的参数矩阵,k是类别数,所以w中的每一行对应一个类别
Pretraining
预训练一个CNN用于特征提取
可以使用监督学习或者孪生网络
从support set中提取特征向量
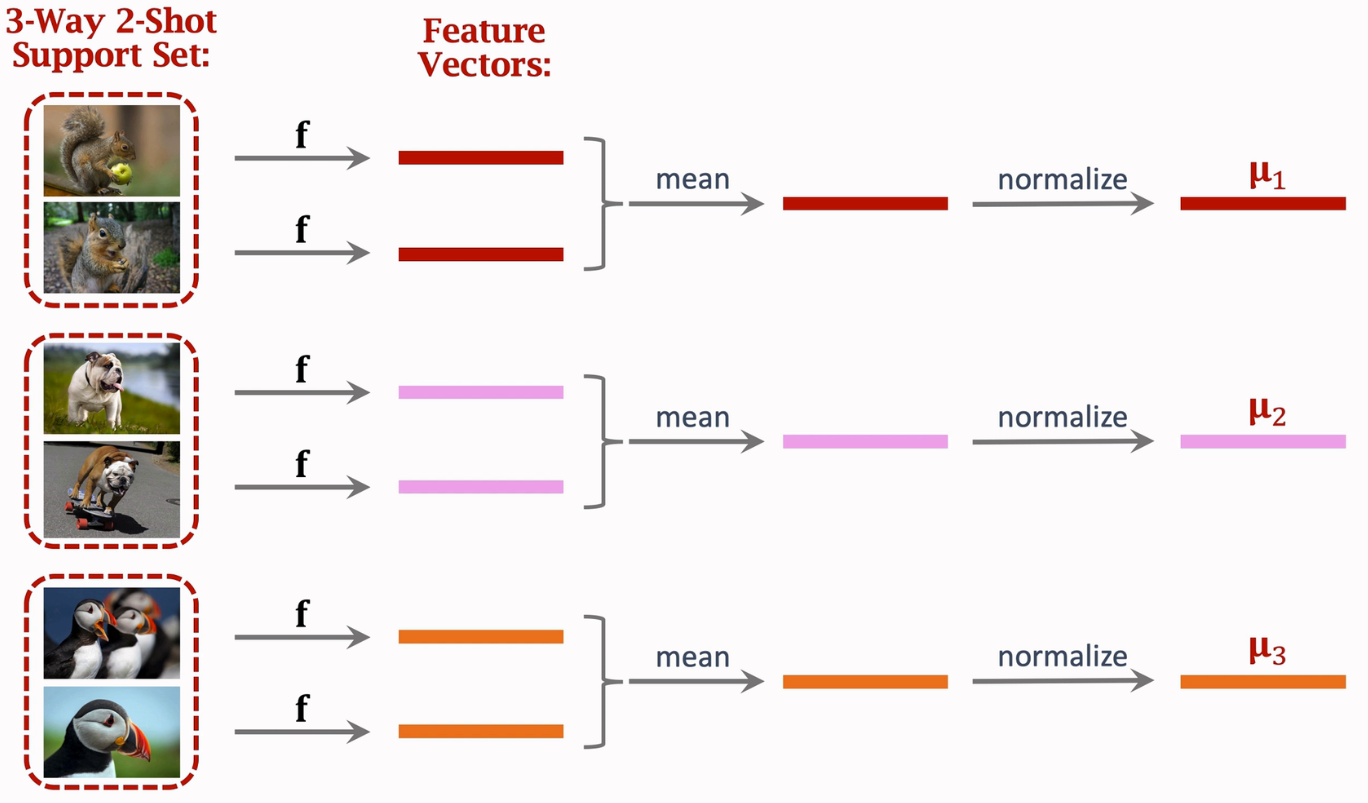
然后利用训练好的网络f提取query图像的特征向量,并标准化/归一化(normalize),得到特征向量q,其2范数为1
将从support set中提取的每个类的平均特征向量作为矩阵M的行向量堆叠起来
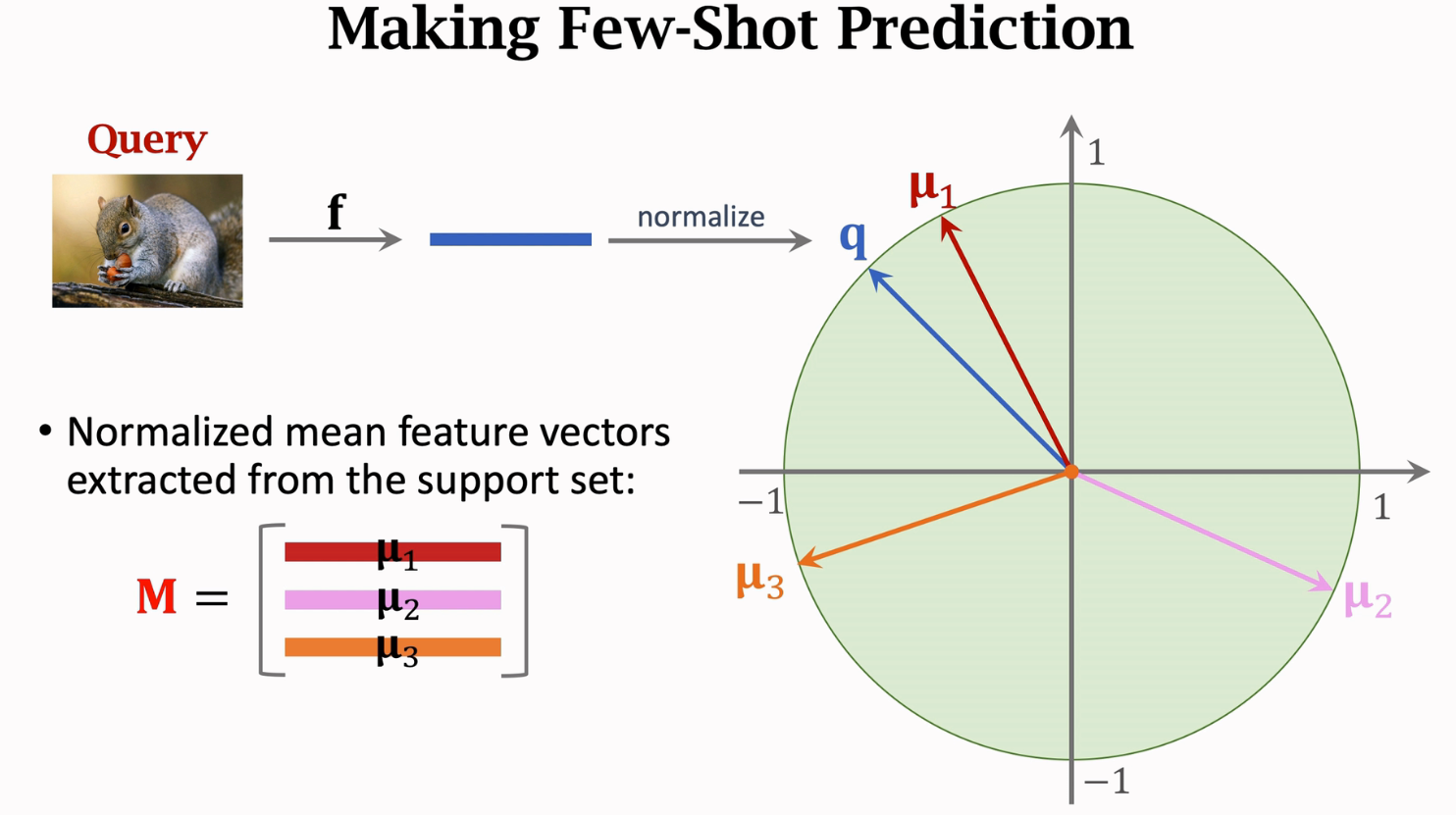
做预测:

结果p应该是个3维的列向量,表示概率分布,表示了query和μ1,μ2,μ3的相似度,其中第一行最大,因为在图中μ1和p是最接近的,其内积最大
Normalization
normalize后的二范数是1(归一化)。Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(比如l1-norm,l2-norm)等于1。
p-范数:即向量元素绝对值的p次方和的1/p次幂,2范数就是p范数的特例
对两个向量的l2-norm进行点积(内积),就可以得到这两个向量的余弦相似性。
L2标准化

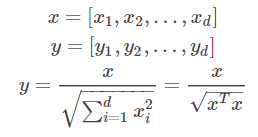
fine-tuning
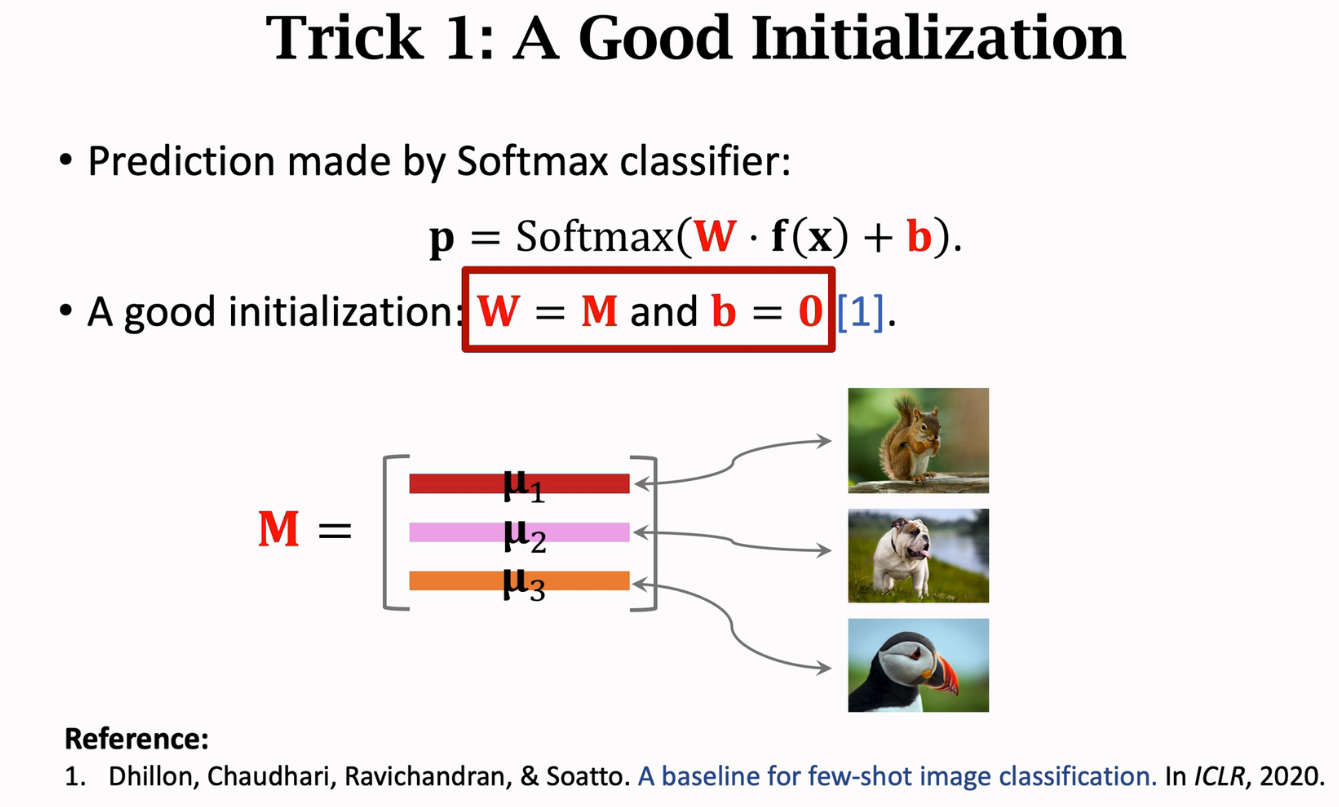
在前面的例子中,我们并没有使用学习的方式得到W和b,而是将W设置为M矩阵,b设置为0,但实际上这两个参数是可以学习的,也就是我们可以对softmax分类器在support set中进行学习,可以使用crossEntropy loss对W和b进行学习,yj是one-hot向量,surrport set一般很小,所以加一个regularization来防止过拟合

做fine-tuning时的trick
- 合理的初始化
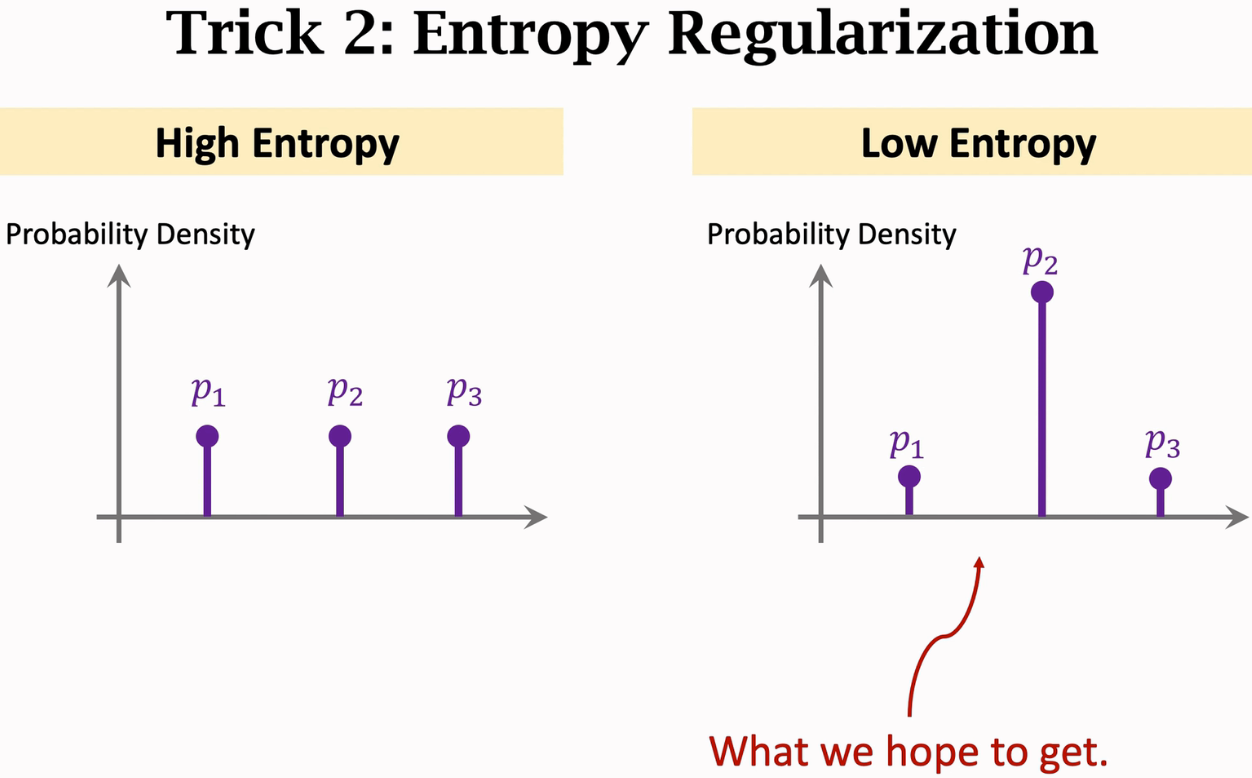
- 用regularization防止过拟合。entropy regularization是其中一种方式,对每个query都求一个entropy,然后求平均,要让这个平均的entropy越小越好,因为熵越小,代表不确定越小,当p的每个维度都相近时,也就是分辨不出来谁的概率更大时,熵最大,不确定性最大

- cosine similarity + softmax classifier。其实和标准的softmax分类器区别很小,只是在做w和q的内积之前,先做归一化。
