CVPR2020 MoCo
Momentum Contrast for Unsupervised Visual Representation Learning
Motivation
无监督表征学习如GPT和BETR在NLP中取得了成功,但在视觉领域有监督的预训练还是占主导地位,作者分析其原因可能是NLP和CV中信号空间的差异,NLP中的单词句子是离散的,可以用于构建tokenized dictionaries(tokenized可以认为把某一个词对应成某一特征),进而进行无监督学习,但在视觉中,信号是在连续的高维空间中的,并不像单词一样具有很强的语义信息,所以不适合建立一个tokenized dictionaries。
无监督学习训练编码器来实现字典查找,也就是使编码的 “query” 与其匹配的”key”更相似,而与其他”key”特征更不相似。作者认为建立的字典需要满足两个特性:
large
较大的字典能更好地采样底层的连续、高维视觉空间(每一个key就相当于是在特征空间中采样了一个点,采样点越多,越能表示整个特征空间分布)
consistent
字典中的key应该由相同或相似的编码器表示,以便它们与query的对比是一致的,如果使用不同的编码器,则可能只是简单找到了一个由与query分支编码器相似的编码器产生的key,也就是shortcut solution
以往的工作往往受限于这两个方面
Methodology
Contrastive Learning as Dictionary Look-up
Pretext task代理任务
无监督学习使用代理任务来生成标签,解决代理任务是为了得到好的特征
MoCo采用个体判别instance discrimination,每张图片自成一类(不同的变换得到正样本,其他都是负样本),然后进行自监督对比学习
一张图片经过两种变换得到两张图片,其中一个作为基准图片$q$(anchor),另一个作为正样本$k_+$,构成正样本对。而$q$与样本集${k_0,k_1,k_2,…}$中除了$k_+$之外的其他样本构成负样本对。
contrastive loss
使用点积来评估相似性,当$q$与positive key $k_+$相似,与其余negative keys不相似时,有较低的值。
softmax操作,一个向量的exponential除以多个向量的exponential的和,z代表logits
$ p_+ = \frac{\exp \left(z_{+}\right)}{\sum_{i=0}^{k} \exp \left(z_{i}\right)}$
cross entropy loss = softmax+log+nll_loss
- 使用softmax对logits进行计算,得到每张图片的概率分布,值为0-1,概率之和为1
- 对softmax的结果取自然对数,因为softmax后的数值为0-1,所以取了ln后值域为负无穷到0
- 然后进行NLL Loss计算,NLL Loss的结果就是将上一步骤的值去掉负号求均值
在有监督学习中,k是类别数量,如ImageNet就是1000类
$L_{CE} = -log\frac{\exp \left(z_{+}\right)}{\sum_{i=0}^{k} \exp \left(z_{i}\right)}$
理论上对比学习也可以使用CE loss,但是在无监督对比学习中,k将变得很大,如在ImageNet中k不再是1000而是128万,因为在这一代理任务中每一个样本自成一个类别,在如此多类别的情况下softmax将无法工作,exp操作的计算复杂度也将非常高,因此行不通。所以提出了NEC(noise contrastive estimation) loss来回避softmax在多类别时的复杂计算,将多分类问题看作多个二分类的组合,并利用采样的方式来估算在整个样本集产生的loss,InfoNCE则是NCE的一个变体,将问题还是视作多分类问题。
InfoNCE
$\mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\sum_{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)}$
$q \cdot k_+$和$q\cdot k_i$相当于logits,$\tau$是温度超参数,用于控制分布的形状,$\tau$变大时,值变小,分布里的值都变小,分布变平滑,$\tau$变小,分布里的值变大,分布变集中,温度设的过大,则对比损失对所有负样本都一视同仁,温度过小,则会使模型过于关注特别困难的样本(可能是潜在的正样本),导致收敛困难或者特征难以泛化。
温度系数只是一个标量,当去掉时,InfoNCE loss就是CrossEntropy loss,只是K的含义不一样,这里的K指的是负样本的数量,这里分母上的sum操作实际上是对1个正样本和K个负样本的求和,也就是从0到K一共K+1个样本,也就是字典里所有的keys,其实InfoNCE loss就是一个在做K+1类的分类任务的CE loss,目的是把$q$正确分类成$k_+$这个类别。
在代码中,InfoNCE loss的实现也是基于CE loss实现的
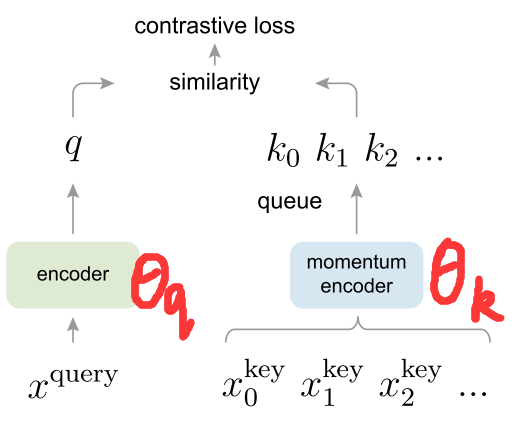
Momentum Contrast
为了实现large和consistent,MoCo使用队列和移动平均编码器来构建了一个动态字典:
使用队列来建立字典,每更新一个mini-batch的keys并将其加入队列,就把队列的头部最早的mini-batch出队,这样就实现了字典大小和mini-batch大小的解耦(也就是字典大小和mini-batch大小是分开的,因而可以将字典的大小设的非常大)。
由于队列中只用当前的mini-batch的keys是由当前的编码器得到的,而之前产生的keys都是由不同时刻的编码器所产生的,这就产生了不一致。MoCo使用momentum encoder来实现consistent,这也是与以往工作的最大区别
Momentum可以理解为加权移动平均,momentum encoder的参数更新可以表示为$\theta_k=m\theta_{k-1}+(1-m)\theta_q$, $\theta_q$代表query分支编码器的参数,$\theta_k$代表key分支的momentum encoder的参数,动量编码器$\theta_k$刚开始是由$\theta_q$初始化而来,但在模型训练过程中,作者选择了一个大的动量m(如0.999),那么动量编码器$\theta_k$的更新是非常缓慢的,不会跟随$\theta_q$快速改变,从而保证了keys的一致性(也就是由相似的编码器抽取得到的)
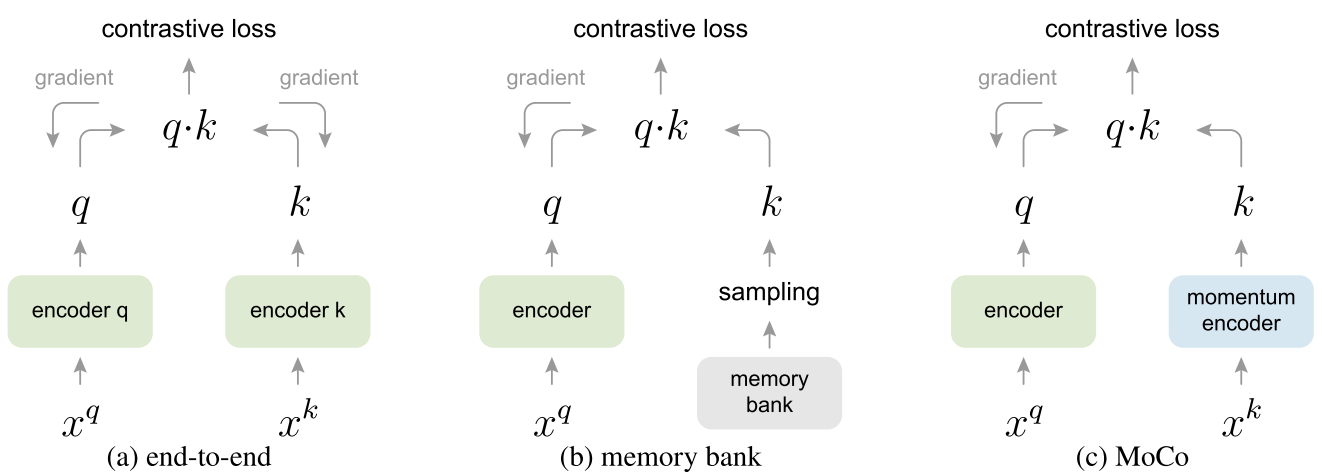
下图中展示了以往方法和MoCo架构上的不同
- (a)end-to-end。q和k的编码器都是通过端到端学习反向传播得到的,输入$x^q$和$x^k$都是从同一个mini-batch中来的,且使用相同的编码器,所以能够保证一致性,但是受限于字典大小,因为在这一架构中,字典大小和mini-batch大小是等价的,典型的方法是SimCLR。总结来说,优点在于编码器可以实时更新,所以字典中的keys的一致性非常高,缺点在于字典大小就是mini-batch大小,所以限制了字典的大小
- (b)memory bank。牺牲了一致性,提升了字典大小,q的编码器通过梯度回传得到,k分支则是没有单独的编码器的,是将整个数据集的特征存储下来,如对于ImageNet,则是存下128万个特征,每个特征128维。每次训练则是从字典里随机抽样出k。因为每次抽样k然后与q计算完loss后,梯度回传更新q的编码器,然后使用编码器对抽取的这几个k的特征进行更新,这意味着要一整个epoch才能将整个memory bank更新一遍,所以memory bank中的特征一致性比较差
伪代码
1 | # f_q, f_k: encoder networks for query and key |
detail
学习率设为30,有些反常