对比学习串烧
基于对比学习的方法通过使相同实例的相似样本或各种增强彼此接近,而不相似实例彼此远离来学习特征表示。
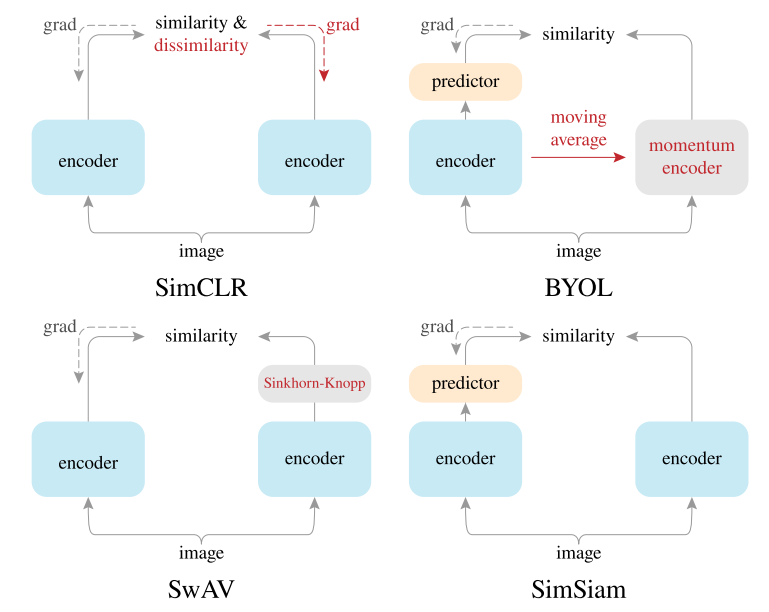
基于相似性的自监督学习方法如BYOL,通过最小化同一实例的不同增强之间的距离来学习特征表示,并且仅使用正样本对。
InstDisc
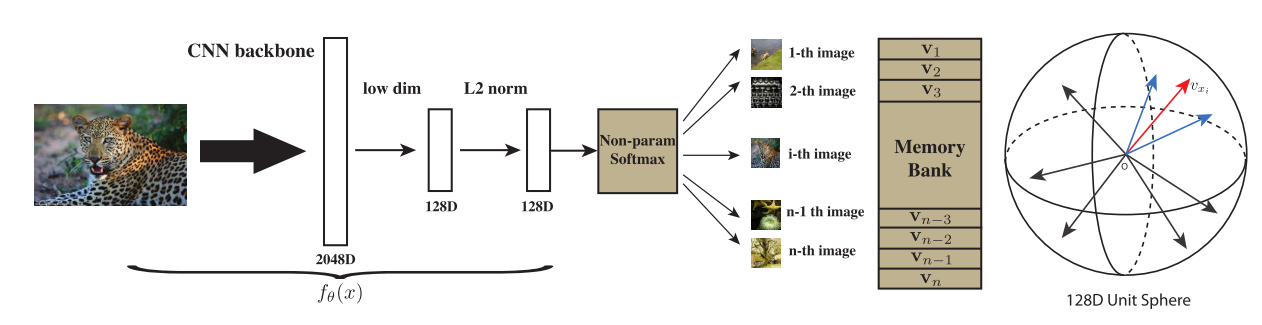
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
提出了个体判别代理任务,和NCE loss结合进行对比学习,取得了不错的无监督表征学习结果,还提出使用memory bank来存储负样本,并对特征进行动量更新(Proximal Regularization)
CVPR2019 InvaSpread
Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
SimCLR的前身,没有使用额外的数据结构来存储大量负样本,正负样本来自于同一个mini-batch,而且只使用一个编码器来进行端到端学习
Motivation:同一实例在不同数据增强下的特征应该是不变的Invariant(相似的),而不同实例的特征应该是分离的Spreading(不相似)。
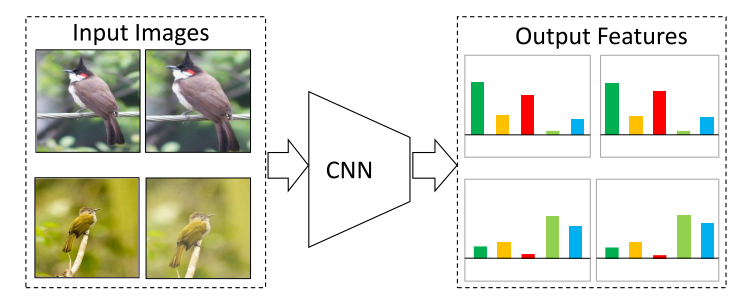
代理任务仍然是个体判别,正负样本来自同一mini-batch,如batch-size设置为256,则正样本有256个,负样本有$(256-1)\times2$个,即正样本就是自己的数据增强版本,负样本是同一mini-batch中其他图片及其数据增强版本。这样做的好处是可以使用端到端学习,并且只使用了一个编码器,不需要借助其他数据结构来储存。但由于batch-size小,负样本数量有限,效果并不惊艳。
CPC
Representation Learning with Contrastive Predictive Coding
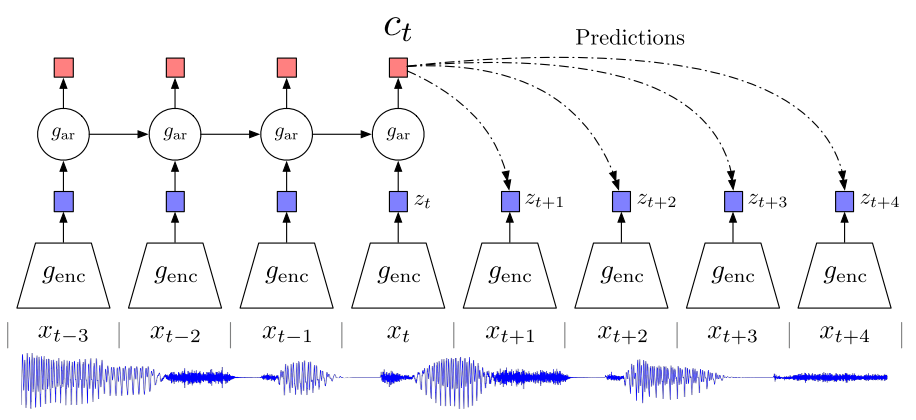
个体判别属于判别式的代理任务,本文采用的则是生成式的代理任务,预测
CPC的结构是个普适性的结构,用于处理序列,在图像中就是将图像切成patch,然后变成序列。使用自回归模型预测序列的未来输出。
$c_t$指通过自回归模型(RNN,LSTM等)编码得到的上下文特征,这一特征可以被用来预测输入序列的未来时刻的编码后的特征也就是$z_{t+1},z_{t+2}…$。在CPC中,$c_t$进行对比学习的正样本就是未来时刻的特征输出$z_{t+1},z_{t+2}…$,负样本则是任意输入经过编码器得到的特征。
CMC
Contrastive Multiview Coding
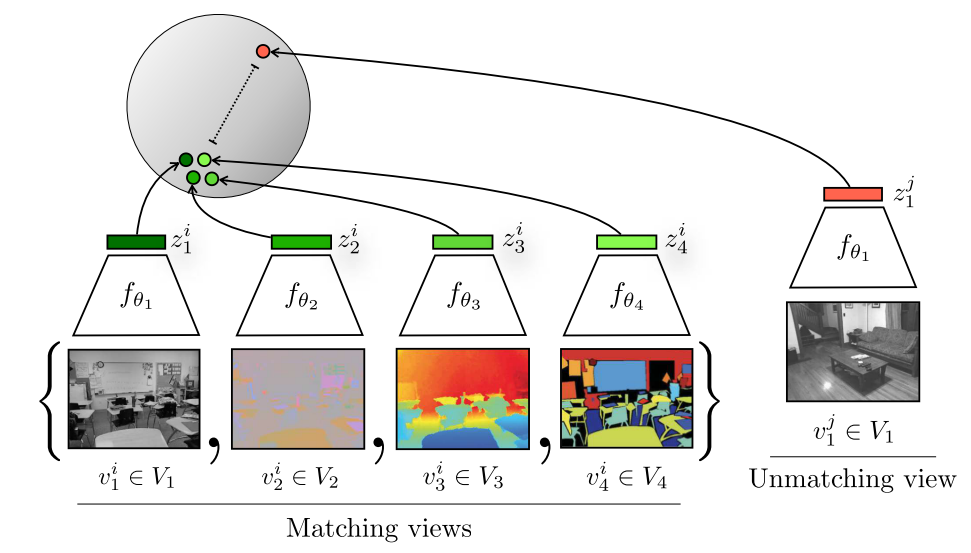
一个物体的多个视角都可以被看作是正样本,每个视角可能都是带有噪声且并不完整的,但是最重要的信息在多个视角下都是共享的,CMC想要学习一个强大的特征,具有视角的不变性,旨在增大多视角之间的的互信息。
CMC选择了NYU RGBD数据集进行实验,其包括4个视角:原始图像,深度图像,surface normal,分割图像。虽然输入是不同的模态,但都是对应同一张图像,所以互为正样本,在特征空间中应该相近,与不匹配的视角图像应该远离。
需要注意的是,由于是多个模态,输入差别较大,所以可能需要使用不同的编码器对不同模态进行处理。
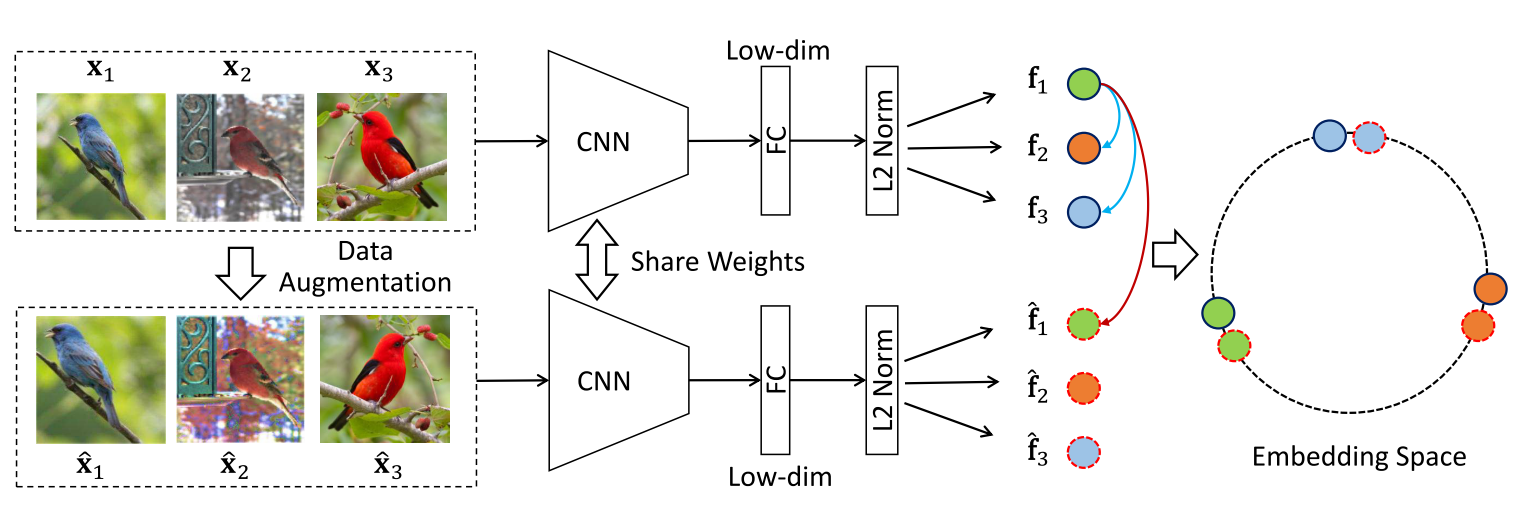
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
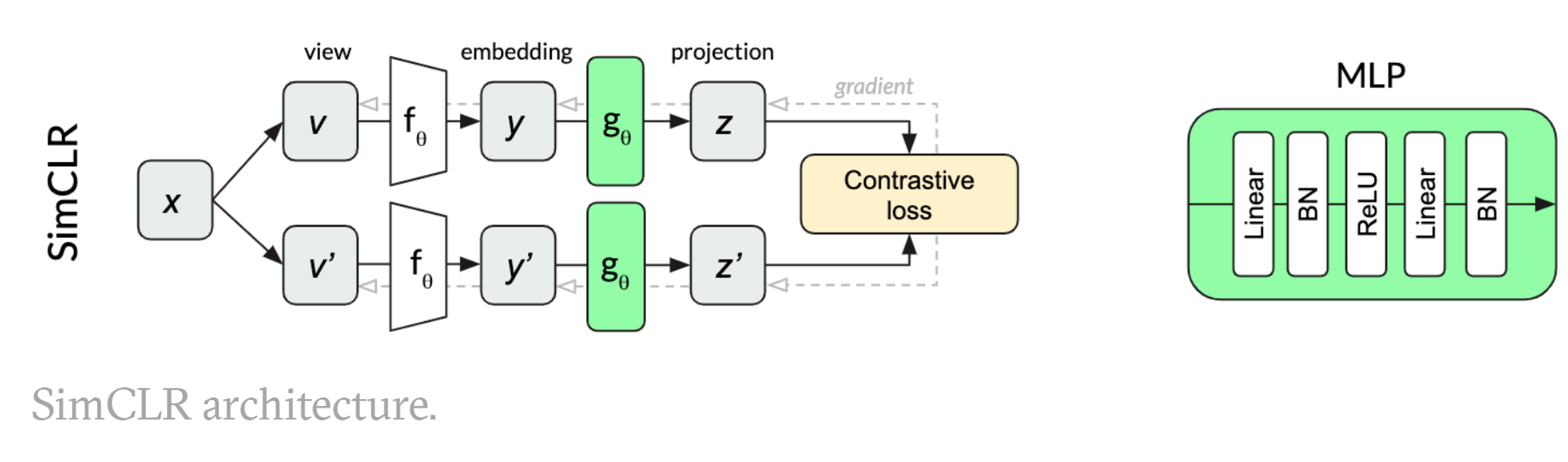
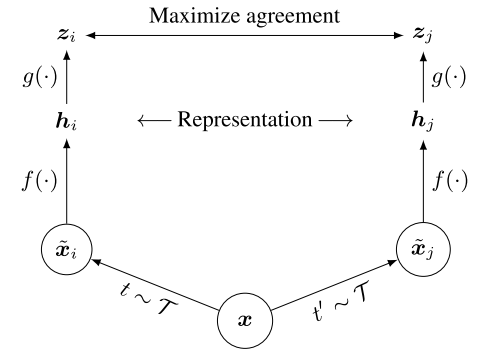
SimCLR的正负样本定义与InvaSpread一样,正样本就是自己的数据增强版本,负样本是同一mini-batch中其他图片及其数据增强版本。SimCLR提出的一个重要的创新点是,在编码器$f$编码得到特征$h_i$和$h_j$之后,加上了一个projector(做非线性变换,有relu),也就是$g$,其实是个mlp(全连接层加relu).除此之外,相比于InvaSpread,SimCLR使用了更强的数据增强手段,以及更大的batch sizes。
采用了多种数据增强方式,其中最有效的是随机裁剪和随机色彩变换

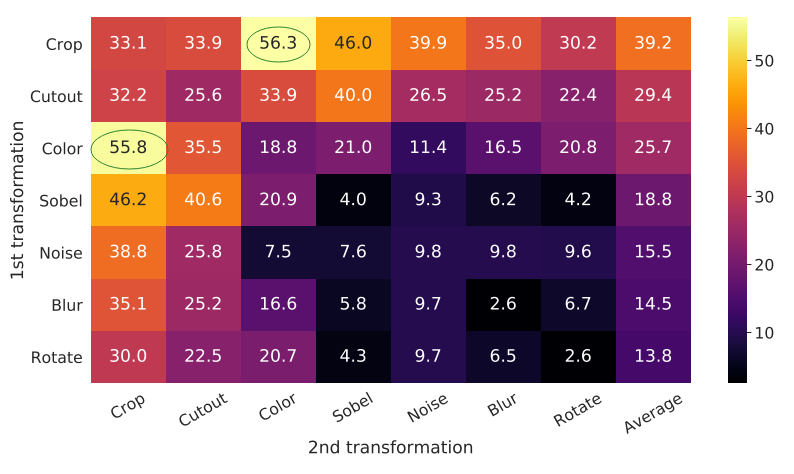
MoCo v2
在MoCo v1基础上,借鉴了一些SimCLR的技术,如MLP,更多的数据增强,并使用cosine learning rate,训练更长时长
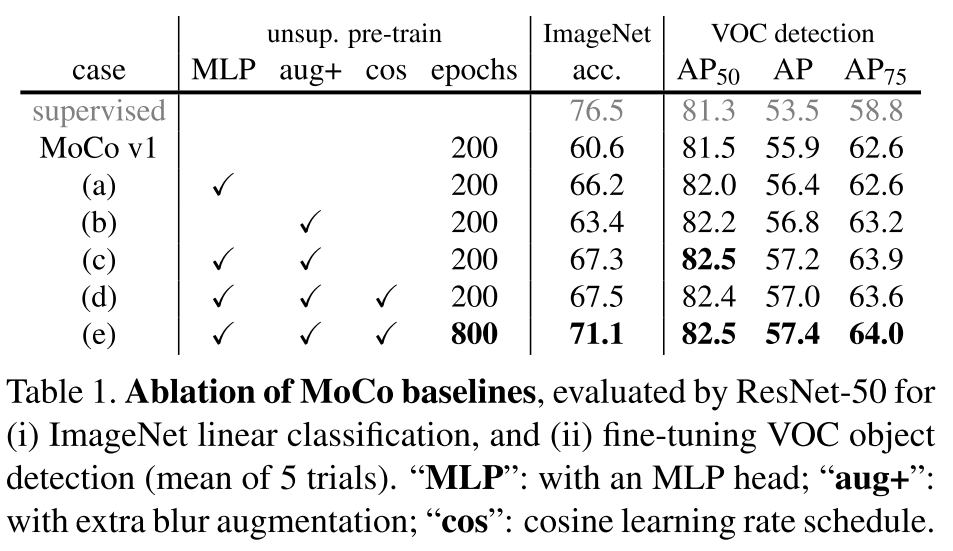
SimCLR v2
Big Self-Supervised Models are Strong Semi-Supervised Learners
用了更大的模型,更强的backbone,mlp由一层变为两层,加了动量编码器
SwAV
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
Swapped Assignment Views,希望用一个视角得到的特征去预测另一个视角,将匹配问题换成了预测问题
SwAV将对比学习和聚类结合在一起,并不直接和大量的负样本比(如moco中的6万个负样本,去近似128万的ImageNet),而是和聚类中心比(本文选取K=3000个聚类中心,就是图中的Prototypes $C$,是一个$D\times K$的矩阵,D代表特征维度,与$z_1,z_2$的特征维度是一致的,K=3000)
代理任务:当$X_1,X_2$是正样本时,$z_1,z_2$的特征应该很相似,应该是可以互相预测的,这也是Swapping Assignments between Views的含义。因此,SwAV将$z_1$和$C$做点乘然后去预测$Q_2$,将$z_2$和$C$做点乘然后去预测$Q_1$
下图中B代表batchsize,D代表特征维度,K则是聚类中心数量,$Q_1,Q_2$可以视作是GT,使用$z_2,z_1$来交叉预测,然后进行对比学习
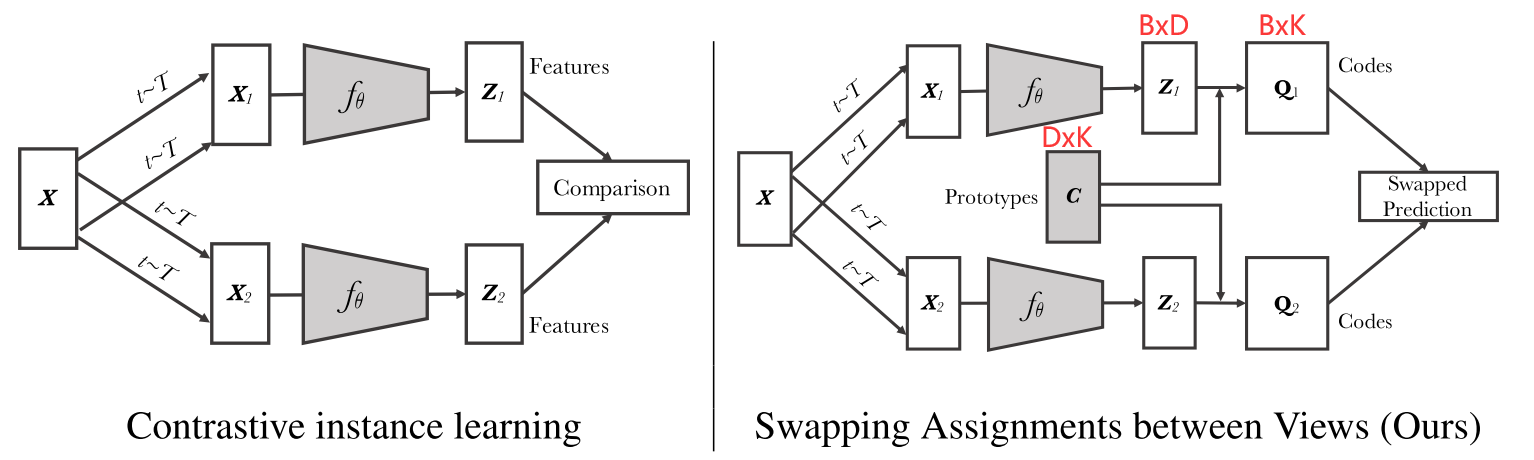
聚类的好处:
- 和很多负样本做类比,对负样本的数量要求很高,而且也只是近似,聚类则只需要少量的聚类中心就可以表示了
- 聚类中心是有明确的语义含义的
Multi-crop技术:
原来的crop往往是先将图像resize到$256\times 256$,然后再随机crop出两个$224\times 224$的区域,由于图片较大,重叠区域多,所以认为是正样本对。大的crop抓住的是整个场景的特征,作者增加了crop的数量,但是由于增加正样本了,模型计算复杂度会变高,因此作者采用了大crop(2个$160\times 160$的crop,学习全局特征)和小crop(4个$96\times 96$,学习局部特征)结合的方式,代替原本的2个$224\times 224$的大crop,使得在得到更多正样本的同时计算代价基本不变
BYOL
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
latent,feature,embedding,hidden都是指特征
对比学习中,负样本能够防止模型坍塌,学到捷径解,也就是将所有样本都预测为一致的。BYOL是第一个不需要负样本的对比学习方法。
对比任务变为预测任务
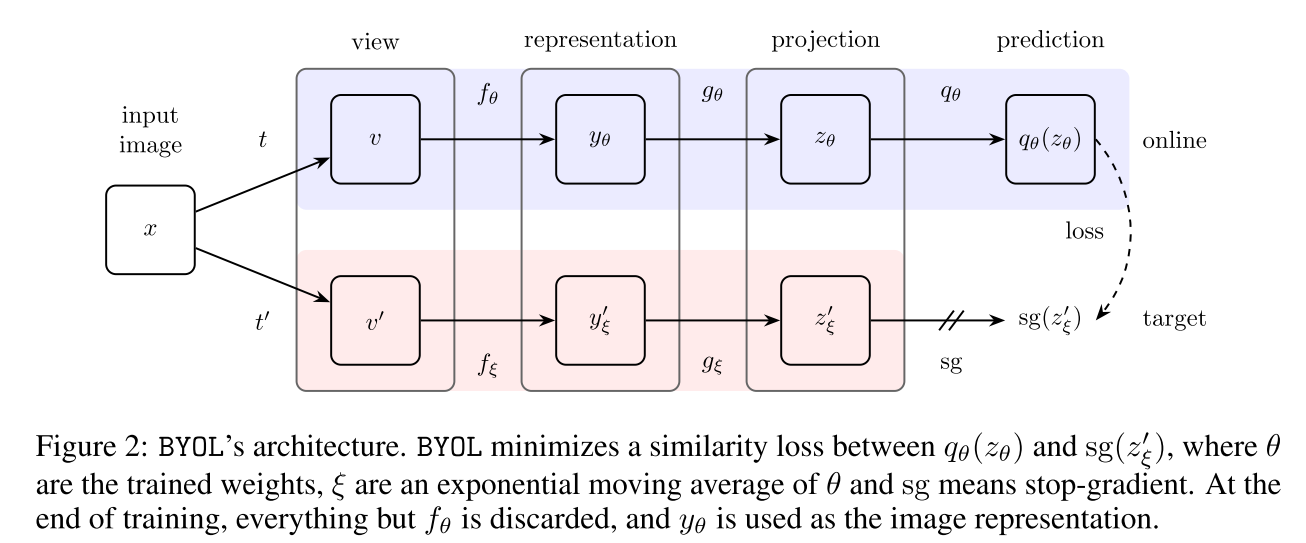
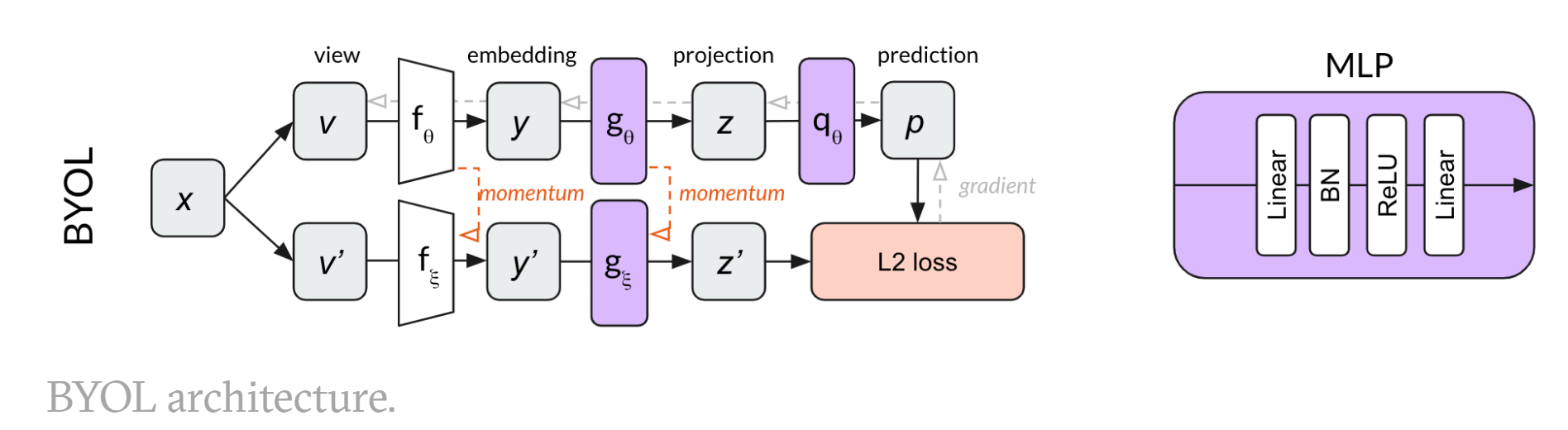
$f_{\theta},g_{\theta}$随着梯度更新而更新,$f_{\xi},g_{\xi}$是动量编码器,projection部分与SimCLR一样就是加了个projector, 之前的对比学习方法,如SimCLR,在得到特征$z_{\theta},z_{\xi}$后,需要使这两个特征尽量接近,而BYOL则是再加入了一个predictor $q_{\theta}$(与$g_{\theta}$结构一致,都是一个MLP),然后使经过预测得到$q_{\theta}(z_{\theta})$与$z_{\xi}$尽量一致,直接使用MSE loss进行优化,将原来的匹配问题转换为了预测问题
SimSiam
Exploring Simple Siamese Representation Learning
- 不需要大的batch size
- 不需要负样本
- 不需要动量编码器
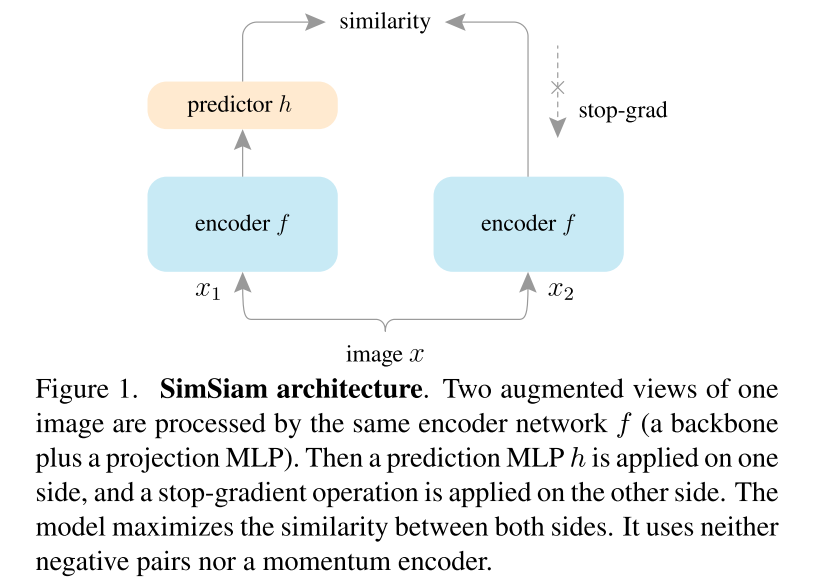
与BYOL结构非常相似,只是没有使用动量编码器
伪代码
negative cosine similarity loss其实就是MSE loss

SimSiam可以成功训练,不会发生模型坍塌,主要是因为stop gradient操作的存在,可以把SimSiam看作EM算法,逐步更新,避免坍塌
MoCo v3
An Empirical Study of Training Self-Supervised Vision Transformers
提高ViT训练的稳定性
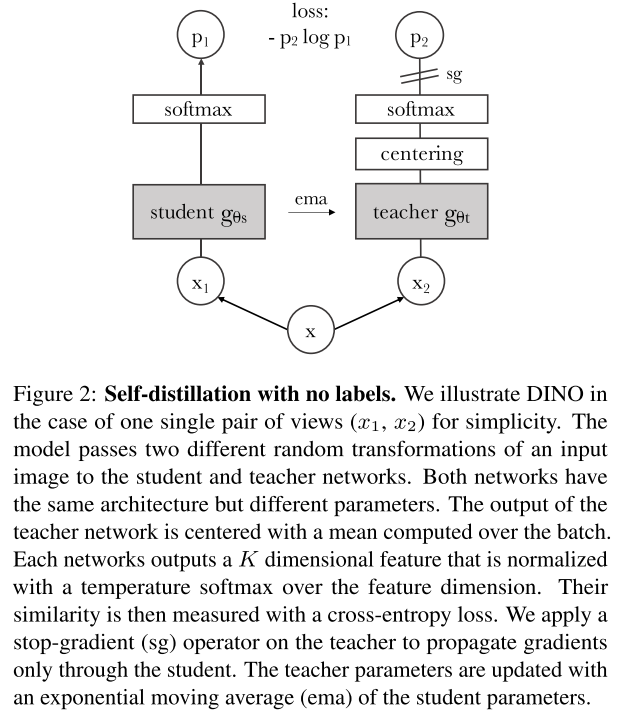
DINO
Emerging Properties in Self-Supervised Vision Transformers