CVPR2022 CLIMS
Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Motivation
CAM通常仅激活判别性对象区域,并且错误地包含许多与对象相关的背景。WSSS模型仅可用一组固定的image-level对象标签进行训练,因此很难抑制由开放集对象(open set objects)组成的不同的背景区域。
WSSS往往由3个阶段:
- 训练并产生CAM
- 细化CAM,生成伪标签
- 使用伪标签训练一个分割网络
由于在close-world setting中,和目标密切相关的背景有助于目标对象的分类,比如背景铁轨和目标对象火车,这会导致CAM不必要的激活背景,此外,CAM还会struggles in the underestimation of object contents。这限制了初始CAM的质量。
CLIM框架的核心思想是引入自然语言监督来激活更完整的对象区域并抑制密切相关的开放背景区域
Methodology
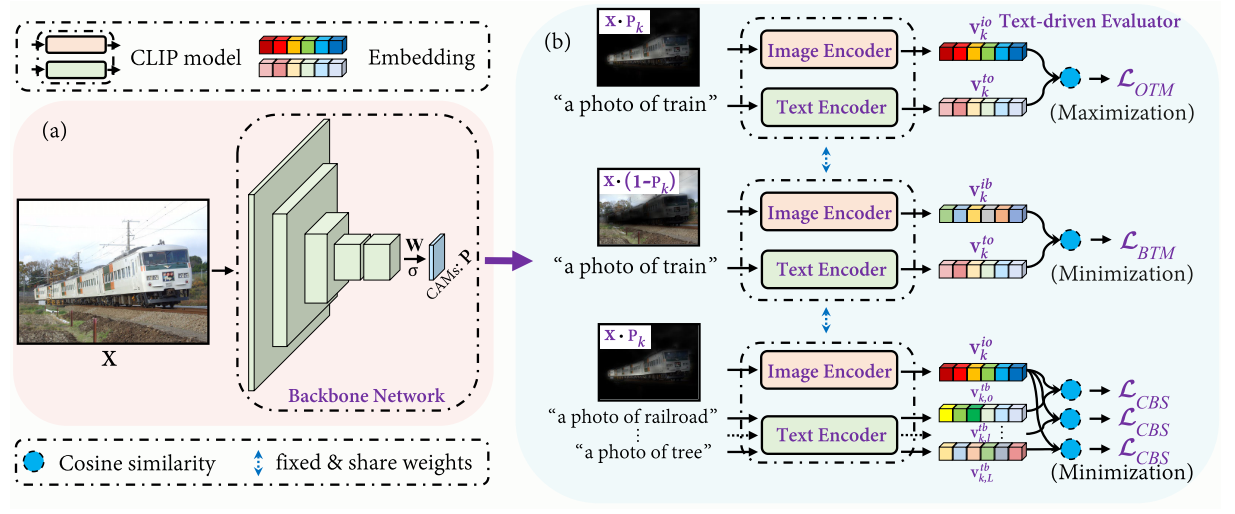
Framework
Backbone Network
CLIM在CAM的基础上,去掉了GAP,并使用sigmoid进行了归一化,得到k个类别的激活图(CAMs) $\mathbf{P}$:
$\mathbf{P}_{k}(h, w)=\sigma\left(\mathbf{W}_{k}^{\top} \mathbf{Z}(h, w)\right)$
W指全连接层,Z是最后一层卷积输出的特征图。
Text-driven Evaluator
Text-driven Evaluator使用了CLIP model,包含图像编码器$f_{i}(\cdot)$和文本编码器$f_{t}(\cdot)$。
首先利用$\mathbf{P}$和$1-\mathbf{P}$来屏蔽背景和前景,并送入图像编码器,获得每个类别的图像特征表示,o代表object,b代表background:
$\mathbf{v}_{k}^{i o}=f_{i}\left(\mathbf{X} \cdot \mathbf{P}_{k}\right), \quad \mathbf{v}_{k}^{i b}=f_{i}\left(\mathbf{X} \cdot\left(1-\mathbf{P}_{k}\right)\right)$
与CLIP一样,CLIMs也使用了text prompt(文本提示) “a photo of {}”, 在分类的标签基础上,CLIMs还另外预先定义了k个类别密切相关(常常同时出现)的背景类别co-occurring background closely related with the object,并将text prompt后的句子送入文本编码器,获得每个类别的文本特征表示:
$\mathbf{v}_{k}^{t o}=f_{t}\left(\mathbf{t}_{k}^{o}\right), \quad \mathbf{v}_{k, l}^{t b}=f_{t}\left(\mathbf{t}_{k, l}^{b}\right)$
$\mathbf{t}_{k}^{o}$和$\mathbf{t}_{k, l}^{b}$分别表示对象的文本标签和特定类k的第l类相关共出现背景。
1 | background_dict = { |
Object region and Text label Matching
对于前景对象,使图像特征表示和文本特征表示相似度最大化
$\mathcal{L}_{O T M}=-\sum_{k=1}^{K} y_{k} \cdot \log \left(s_{k}^{O O}\right)$
$s_{k}^{o o}=\operatorname{sim}\left(\mathbf{v}_{k}^{i o}, \mathbf{v}_{k}^{t o}\right)$
Background region and Text label Matching
为了提升前景对象激活的完整性,提出了the background region and text label matching loss来寻找更完整的object contents, 使背景的图像特征表示和前景的文本特征表示相似度最小化:
$\mathcal{L}_{B T M}=-\sum_{k=1}^{K} y_{k} \cdot \log \left(1-s_{k}^{b o}\right)$
$s_{k}^{b o}=\operatorname{sim}\left(\mathbf{v}_{k}^{i b}, \mathbf{v}_{k}^{t o}\right)$
当这一损失变小时,意味着在$\mathbf{X} \cdot\left(1-\mathbf{P}_{k}\right)$中保留了更少的目标对象像素,在$\left(\mathbf{X} \cdot \mathbf{P}_{k}\right)$中恢复了更多的目标对象内容。
Co-occurring Background Suppression
上述两个损失函数仅确保P完全覆盖目标对象,而没有考虑共同发生的类相关背景的错误激活。
因此,CBS则是使前景对象的图像特征表示和背景的文本特征表示的相似度最小化。
$\mathcal{L}_{C B S}=-\sum_{k=1}^{K} \sum_{l=1}^{L} y_{k} \cdot \log \left(1-s_{k, l}^{o b}\right)$
$s_{k, l}^{o b}=\operatorname{sim}\left(\mathbf{v}_{k}^{i o}, \mathbf{v}_{k, l}^{t b}\right)$
Area Regularization
在只有$\mathcal{L}_{O T M}, \mathcal{L}_{B T M} $,和$ \mathcal{L}_{C B S}$时,如果激活映射中同时包含了不相关的背景和目标对象,CLIP仍然可以正确预测目标对象。因此,作者还提出了一个像素级区域正则化项来约束激活图的大小,以确保在激活图中排除不相关的背景:
$\mathcal{L}_{R E G}=\frac{1}{K} \sum_{k=1}^{K} S_{k}, \quad \text { where } \quad S_{k}=\frac{1}{H W} \sum_{h=1}^{H} \sum_{w=1}^{W} \mathbf{P}_{k}(h, w)$
Overall
$\mathcal{L}=\alpha \mathcal{L}_{O T M}+\beta \mathcal{L}_{B T M}+\gamma \mathcal{L}_{C B S}+\delta \mathcal{L}_{R E G}$
用4个超参来调整各loss的权重
Contributions
- 通过直接使用CLIP来引入文本监督
- 利用CLIP来对open-world setting下WSSS方法中错误激活的背景进行抑制