CVPR2017 OICR
Multiple Instance Detection Network with Online Instance Classifier Refinement
Motivation
WSDDN存在的问题:
最终图像分类分数是proposals分数的加权和。深度网络即使只“看到”对象的一部分也可以正确分类图像,因此排名靠前的proposals可能无法满足标准的对象检测要求(ground truth 和预测框之间的 IoU>0.5)
- 对于类内差别大的物体(如人、猫等),proposal得分高的往往是仅包含数据集中图片中物体相对变化较小的部分(如脸部),往往只是对象的一个局部区域,所以检测器更倾向于聚焦在物体的局部区域
- 如果同个类别有多个物体,其中一个物体特别显著,就会导致这个物体的proposal得分相对其他的同类别物体的proposal得分造成碾压,这样就会丢失其他物体。

Motivation:目标检测器可能仅捕获到了对象的一部分,但与检测到的部分高度空间重叠的proposals可能会覆盖整个对象,或者至少包含对象的较大部分。
Our motivation is that, though some detectors only capture objects partially, proposals having high spatial overlaps with detected parts may cover the whole object, or at least contain larger portion of the object.
作者提到需要解决的两个问题:
- 如何初始化实例标签
- 如何有效地训练instance classifier实例分类器
Methodology
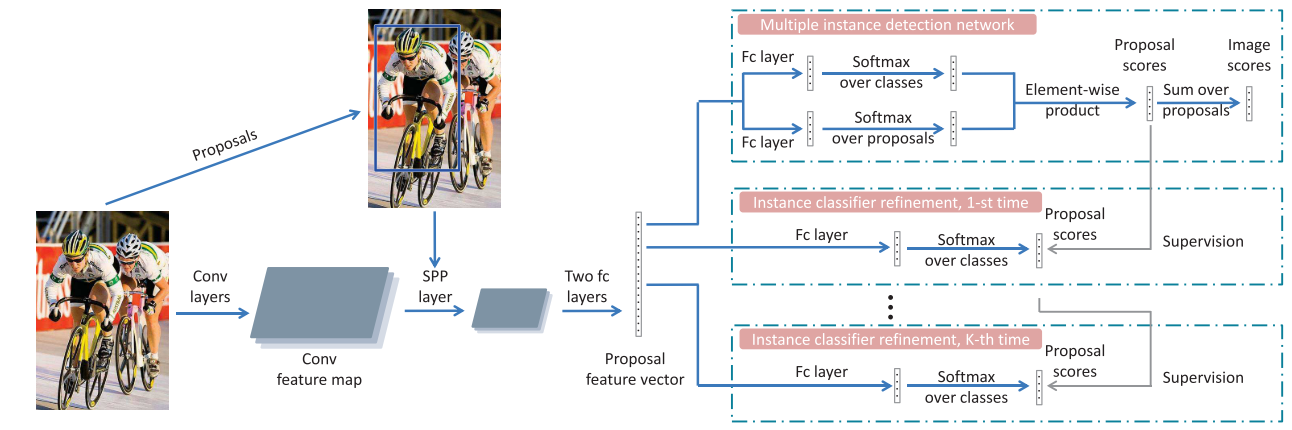
OICR将WSDNN作为baseline,proposal/instance特征由图像卷积特征图上经SPP空间金字塔池化层和两个全连接层生成。这些proposals的特征向量被输入到代表不同阶段的多个分支:第一个分支是基本的多实例检测网络MIDN,其他分支用于对实例分类器进行细化。分类器细化分支的监督由其前一阶段的输出提供。所有这些阶段共享相同的proposal特征表示。
Instance classifier refinement需要instance-level的监督,作者首先引入MIDN来生成基本的实例分类器,将其得分最高的proposals和其相邻proposals作为实例标签监督信息。

Input:输入图像$X$及其proposals;图像标签$Y$;细化$K$次
Output: 对于proposal $r$和第$k$次细化, loss中权重$w_r^k$; proposal label vectors (one hot向量)$Y_j^k=\left[y_{1 j}^{k}, y_{2 j}^{k}, \ldots, y_{(C+1) j}^{k}\right]^{T} \in \mathbb{R}^{(C+1) \times 1}$
3: 初始化第r个proposal与其他proposal的最大重叠度为-inf
4: 将提供给下一个分支使用的proposals的标签(instance-level pseudo label)除背景类置为1,其他类别全置为0
567: 对于每一个类别,如果图片有类别c的标签(image-level),则根据上一个分支输出的矩阵$x_{cr}^{R(k-1)}$选择出最高得分的proposal,将下表记作$j_c^{k}$(注意 $j_{c}^{k-1}=\arg \max _{r} x_{c r}^{R(k-1)}$)
89: 对于每一个proposal r,计算当前proposal r和proposal $j
_c^k$的IOU记为$I^{‘}_r$
10,11: 出现最大重叠度时,则更新最大重叠度$I_r$,并将下一分支中proposal r的权重$w_r^{k+1}$更新为当前分支k输出矩阵$x_{c r}^{R(k-1)}$第$j_c^{k}$个proposal的c类别的得分,这样就实现了小proposal向重叠的大proposal传递标签信息的目的(增大大proposal的权重)
12,13: 判断最大重叠度$I_r$是否大于给定重叠度阈值$I_t$,如果大于的话则下一分支proposal r的监督信息把c类别置为1,其他类别置为0
$\mathrm{L}_{\mathrm{r}}^{k}=-\frac{1}{|R|} \sum_{r=1}^{|R|} \sum_{c=1}^{C+1} w_{r}^{k} y_{c r}^{k} \log x_{c r}^{R k}$
OICR中作者把跟top1得分的proposal IOU较大proposals都打上相同的类别标签,并且使用top1的得分作为这个类别所有proposals loss的权重,这样做可以使得大proposals的概率值提高,但并不能保证一定会超过小proposals,作者实验k分支使用k的大小,发现k=3的性价比是最高的,而k>3目标检测性能提高很小,这是因为这后面的k分支学习是严重依赖于基础网络Multiple instance detection network的预测结果的,换句话说基础网络的性能已经饱和了,后面的分支再怎么学也无法提高性能。参考