CVPR2016 WSDDN
Weakly Supervised Deep Detection Networks
Background&Motivation
MIL交替执行对象外观学习和区域选取
MIL 策略导致非凸优化问题:在实践中,求解器往往会陷入局部最优解,因此解的质量很大程度上取决于初始化。
WSDDN提出了一个端到端的WSOD方法,同时执行区域选择和分类,将CNN与MIL结合
Methodology
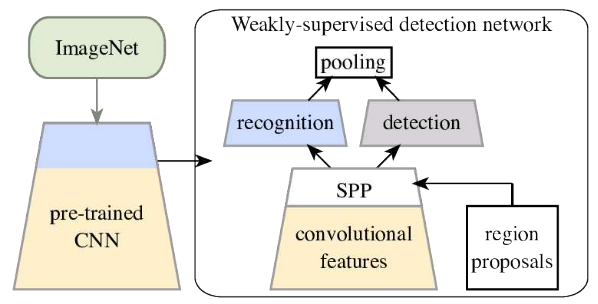
总体思路包括三个步骤。
- 获得一个针对大规模图像分类任务进行预训练的 CNN。
- 在CNN 的架构基础上构建 WSDDN
- 在目标数据集上训练/微调 WSDDN(仅使用image-level标注)
预备知识:
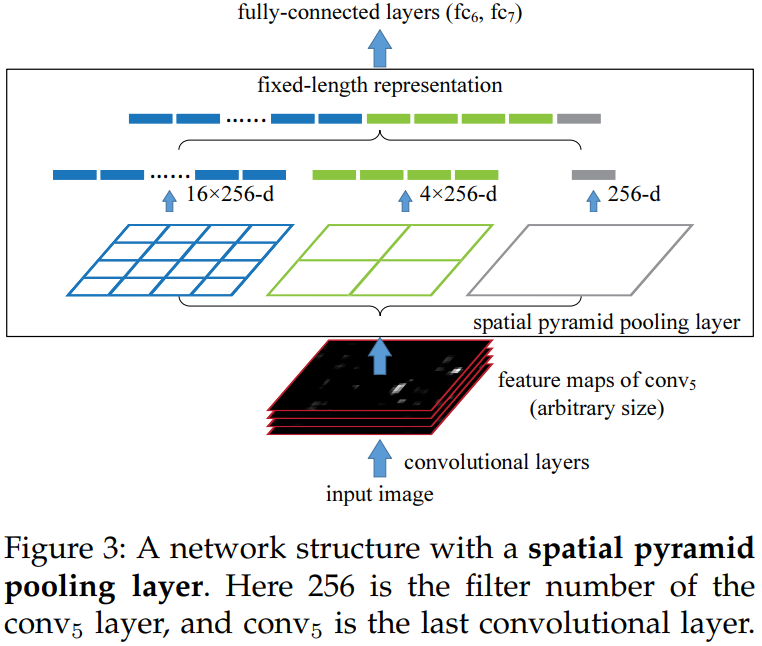
SPP:spatial pyramid pooling,将输入特征图划分为固定的窗口数量,然后使用对应大小池化核进行池化,将不同尺寸池化的结果进行拼接,从而将不同输入尺寸的特征图转换为固定长度的特征向量。
Region Proposals:使用了Selective Search Windows (SSW) and Edge Boxes(EB)两种方法
Hadamard Product (Element -wise Multiplication, Element-wise product):两个向量的Hadamard乘积非常类似于矩阵加法,将给定向量/矩阵的同行同列对应的元素乘在一起,形成一个新的向量/矩阵。
具体算法流程
首先使用预训练的CNN进行特征提取,获得整张图像的特征图,并使用如Selective Search或者EdgeBoxes等传统的Proposal方法产生的R个(~2k)proposals。然后将region proposals特征送入SPP,获得R个proposal对应的R个特征向量,然后经过fc6和fc7两个全连接层映射,作为recognition和detection两个分支的输入。也就是下图中的第一行classification数据流和第二行detection数据流。

Classification data stream:将每个region proposal的特征映射到类别分数的 C 维向量(C个类别),完成分类。其中$\mathbf{x}^{c} \in \mathbb{R}^{C \times|\mathcal{R}|}$,也就是R个proposals属于C个类别的概率。然后对C维度进行softmax得到$\sigma_{class}$。
$\left[\sigma_{\text {class }}\left(\mathbf{x}^{c}\right)\right]_{i j}=\frac{e^{x_{i j}^{c}}}{\sum_{k=1}^{C} e^{x_{k j}^{c}}}$
Detection data stream:其中$\mathbf{x}^{d} \in \mathbb{R}^{C \times|\mathcal{R}|}$,对R维度进行softmax得到$\sigma_{det}$。可以理解为每个proposal对特定类别c分类的贡献度
$\left[\sigma_{\operatorname{det}}\left(\mathbf{x}^{d}\right)\right]_{i j}=\frac{e^{x_{i j}^{d}}}{\sum_{k=1}^{|\mathcal{R}|} e^{x_{i k}^{d}}}$
在Classification data stream中,softmax 算子独立地比较每个region proposal的类分数,而在第二种情况下,softmax 算子独立地比较每个类在不同的region proposal的分数。因此,第一个分支预测将哪个类关联到一个区域,而第二个分支选择哪些区域更有可能包含信息图像片段。
Combined region scores and detection:在获取上述的$\sigma_{class}$和 $ \sigma_{det}$两个矩阵后,进行element-wise product,也就是对应位置相乘,进行信息融合,获得$\mathbf{x}^{\mathcal{R}}$
$\mathbf{x}^{\mathcal{R}}=\sigma_{\text {class }}\left(\mathbf{x}^{c}\right) \odot \sigma_{\operatorname{det}}\left(\mathbf{x}^{d}\right)$
最后对该矩阵的R维度进行累加(意思是每个proposal对类别c的贡献度加起来就表示图片中有c类物体的概率)得到整张图片的分类概率分布,然后与ground truth计算交叉熵损失
由于最后进行损失计算时,是将两个分支进行了融合,似乎并未对detetion分支和classfication分支做针对性的约束。文章中提到了这一融合方式与双流网络的区别:
- softmax算子显式破坏了两分支的对称性,区别于双流网络中高度对称的结构
- 使用element-wise product而不是outer product,计算量更小
- 针对特定图像区域 r 而不是针对网格上的一组固定图像位置计算。
作者认为,这三个差异意味着可以将$ \sigma_{det}$解释为对区域进行排名,而$\sigma_{class}$对类别进行排名。