CVPR2022 从注意力中学习亲和力
Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
(从注意力中学习亲和力:使用 Transformers 的端到端弱监督语义分割)
github
Abstract
WSSS目前的方法主要基于卷积神经网络,无法正确探索全局信息,因此通常会导致对象区域不完整。在本文中,为了解决上述问题引入了Transformer,它自然地整合了全局信息,为端到端的 WSSS 生成更完整的初始伪标签。受Transformers中的self-attention和语义亲和力之间的内在一致性的启发,作者提出了Affinity from Attention (AFA)模块来从Transformers中的多头自注意力(MHSA)中学习语义亲和力。然后利用学习到的亲和力来细化初始伪标签以进行分割。此外,为了有效地导出可靠的亲和标签来监督 AFA 并确保伪标签的局部一致性local consistency,作者设计了一个像素自适应细化模块,该模块结合了低级图像外观信息来细化伪标签。
Introduction
WSSS方法通常采用多阶段框架,也就是先训练一个分类模型,然后生成类激活图CAM作为伪标签。细化后,伪标签被用来训练一个独立的语义分割网络作为最终模型。
多阶段训练流程复杂缓慢,不够高效。现有的一些端到端的解决方案基本是基于CNN的,CNN对全局特征的获取能力较差。
首先使用Transformer生成CAM作为初始伪标签,以避免CNN的内在缺陷,由于 MHSA 中的语义亲和性很粗糙,作者提出Affinity from Attention (AFA) 模块,旨在导出可靠的伪亲和力标签来监督从Transformer中的 MHSA 学习的语义亲和性。然后使用学习到的亲和力通过随机游走传播来修改初始伪标签,这可以扩散对象区域并抑制错误激活的区域。为了使AFA 导出高度可信的伪亲和标签并确保传播的伪标签的局部一致性,我们进一步提出了一个像素自适应细化模块 (PAR)。PAR 有效地整合了局部像素的 RGB 和位置信息以细化伪标签,从而更好地与低级图像外观对齐。
- 端到端WSSS
- AFA, Affinity from Attention
- PAR, 像素自适应细化模块
Related Work
- WSSS
- Multi-stage
- End-to-End
- Transformer in Vision
- 第一个用于WSOL的方法 TS-CAM
Methodology
使用 Transformer 主干作为编码器来提取特征图。初始伪标签是用CAM生成的,然后用提出的 PAR 进行细化。在 AFA 模块中,我们从 Transformer 块中的 MHSA 导出语义亲和性。 AFA 使用源自精炼标签的伪亲和标签进行监督。接下来利用学习到的亲和力通过随机游走传播来修改伪标签。传播的标签最终用PAR作为分割分支的伪标签进行细化。
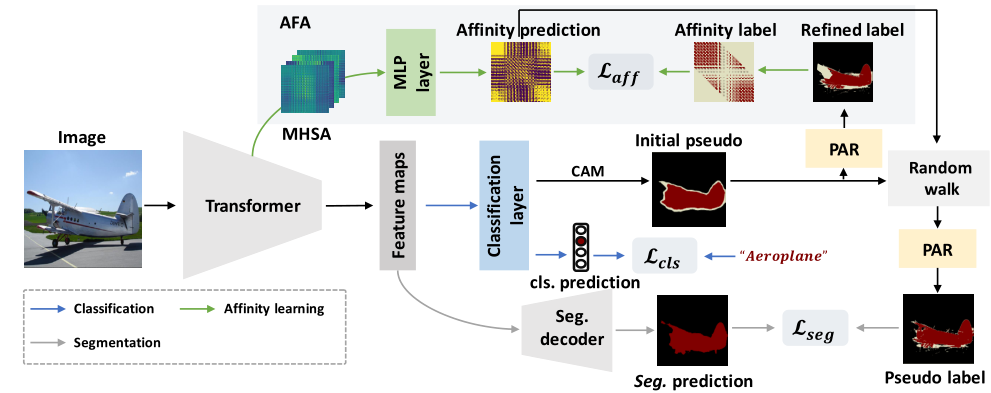
Transformer Backbone
将输入图像分为h x w个patches,然后每个patch被展平并线性投影到h x w个tokens,经过transformer encoder生成特征图供后续使用
CAM Generation
Affinity from Attention(AFA模块)
从attention中学习语义亲和性
由于在训练过程中没有对自注意力矩阵施加明确的约束,因此在MHSA中学习到的亲和力通常是粗糙且不准确的,这意味着直接应用MHSA作为亲和力来细化初始标签效果不佳。
将Transformer block中的MHSA表示为$S\in R^{hw\times hw\times n}$,hw是展平的空间大小,也就是token的数量,n则为注意力头的个数。在AFA中使用MLP对多头产生的注意力图进行线性组合,同时由于亲和力矩阵应该是对称的,而自注意力机制是一种有向图模型,而亲和力矩阵应该是对称的,因为共享相同语义的节点应该是相等的。所以为了将注意力图S转换为亲和力矩阵A,本文采用的操作是将S与其转置相加然后使用MLP进行线性组合$A=MLP(S+S^T)$
亲和力伪标签生成
使用CAM方法生成类激活图后,对类激活图进行细化(使用PAR模块),然后使用两个背景分数$0<\beta_l<\beta_h<1$得到可靠前景,背景和不确定区域,伪标签$Y_p$从CAM中构建:
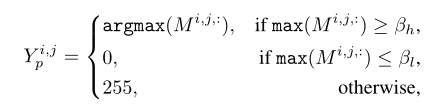
可靠前景(第一行)选取类激活图中通道维最大的序号输出,也就是提取具有最大激活值的语义类
背景 0
不确定区域 255
然后从Yp中得到亲和力伪标签$Y_{aff}$, $Y_{aff}$是hw x hw大小的矩阵,矩阵中的每一位置代表整张图像中2个token间(也就是特征图上的2个像素点)的亲和力。
具体来说,对于 Yp,如果像素 (i, j) 和 (k, l) 共享相同的语义,我们将它们的亲和度设置为正;否则,它们的亲和力被设置为负值。请注意,如果像素 (i, j) 或 (k, l) 是从被忽略的区域中采样的,它们的亲和性也将被忽略。此外,我们只考虑像素(i,j)和(k,l)在同一个局部窗口中的情况,而忽略了远距离像素对的亲和力。
亲和力损失
使用$Y_{aff}$对预测的亲和力矩阵A进行监督
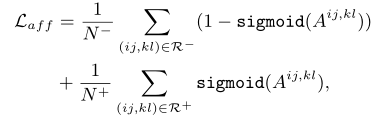
1 | pos_loss = torch.sum(pos_label * (1 - inputs)) / pos_count |
其中R+和R-分别表示$Y_{aff}$中的正样本和负样本集。N+和N-分别代表R+和R-中样本对的数量。
亲和力传播
Weakly supervised learning of instance segmentation with inter-pixel relations. CVPR2019
Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. CVPR2018
与上述两篇文章一样,使用随机游走实现亲和力传播
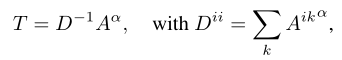
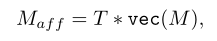
Pixel-Adaptive Refinement(PAR模块)像素自适应细化
基于扩张的像素自适应卷积以结合局部图像外观信息:
PAR模块就是基于这篇文章设计的
Single-stage semantic segmentation from image labels. CVPR2020
保证伪标签的局部一致性
初始伪标签通常是粗糙的并且局部不一致,即具有相似低级图像外观的相邻像素可能不共享相同的语义。为了确保局部一致性,采用dCRF来细化初始伪标签是常见的做法。然而,CRF在端到端框架中并不是一个有利的选择,因为它显着降低了训练效率。受 [4] 的启发,它利用像素自适应卷积PAC提取局部RGB信息进行细化,我们结合RGB和空间信息来定义低级成对亲和力并构建我们的像素自适应细化模块 (PAR)
PAR区别于PAMR的地方主要在于核函数的设计,将rgb和pos信息分开设计了两个核函数,即式8
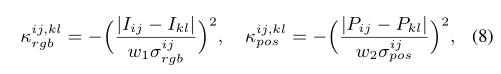
然后使用softmax对两个k进行归一化并求和,在位置核的归一化项前加了一个权重,用于控制对位置的重视程度,即式9
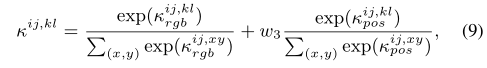
多次迭代细化
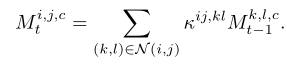
ij处的激活值通过定义的亲和力核k与上次迭代中kl处的激活值联系起来,N是个8领域区域
训练
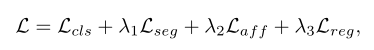
使用了如下文章中使用的正则化损失。这确保了分割预测的局部一致性。
On regularized losses for weakly-supervised cnn segmentation ECCV2018
Reliability does matter: An end-to-end weakly supervised semantic segmentation approach. AAAI2020
Dynamic feature regularized loss for weakly supervised semantic segmentation.
Adaptive affinity loss and erroneous pseudo-label refinement for weakly supervised semantic segmentation. MM2021
实验
使用Mix Transformer (MiT)作为transfomer的backbone
cam使用gap,但在本实验中gmp(global max-pooling)效果更好
1 | # mix_transformer.py Attention的forward函数 |