CVPR2018 AffinityNet
Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
使用图像级监督学习像素级语义亲和度的弱监督语义分割
Abstract
分割标签的不足是进行语义分割的主要障碍之一,在弱监督设定下,训练模型可以分割局部判别部分而不是整个对象区域,本文提出将响应传播到属于同一语义实体的附近区域。提出AffinityNet,预测一对相邻图像坐标之间的语义亲和力。然后通过随机游走将语义传播。
Related Work
- 各类型的弱监督
- 图像级标签的弱监督:一些方法将判别定位技术给出的分割种子与超像素等额外的线索结合,估计物体形状。
- 学习像素级亲和力
- 使用合成标签学习
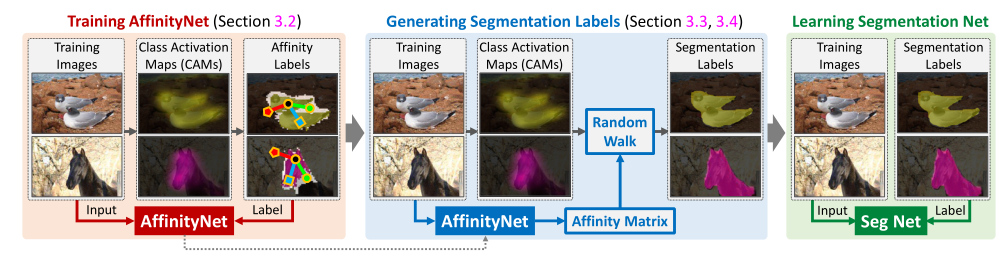
Methodology
整个框架基于三个DNN,第一个网络用于生成CAM,第二个网络用于预测亲和力即AffinityNet,第三个网络是全监督的分割模型,使用合成标签进行训练。
CAM
在CAM基础上,本文定义了背景类的类激活图的计算方式,其中$\alpha$是调节可信的背景区域的超参数,这个参数越大,可信的背景区域就越小。
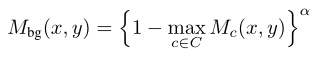
Learning AffinityNet
AffinityNet 旨在预测训练图像上一对相邻坐标之间与类别无关的语义亲和力。预测的亲和力在随机游走中用作转移概率,以便随机游走将 CAM 的激活分数传播到同一语义实体的附近区域,从而显着提高 CAM 的质量。
亲和力定义为特征图两个坐标对应的特征向量L1距离的负值取指数,代表距离越小,亲和力越大,注意公式3中的i和j分别代表特征图上的第i个和第j个特征向量。$(x_i,y_i)$代表第i个特征在特征图上的坐标。
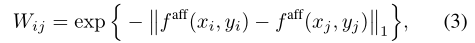
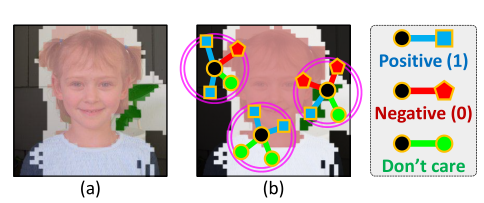
亲和力标签的生成
从CAM中获取监督,思路就是先使用dCRF对CAM进行细化,然后从CAM中的高置信度前景背景中分别采样若干个像素对,根据置信区域确定的类标签为每对坐标分配一个二进制亲和标签。对于非中性的两个坐标 (xi, yi) 和 (xj, yj),如果它们的类相同,它们的亲和标签$W^{*}_{i,j}$为 1,否则为 0。此外,如果至少有一个坐标是中性的,在训练期间简单地忽略这对坐标。
训练过程
AffinityNet 网络通过cam的高置信度区域和背景区域进行训练,语义亲和力标签的生成是在cam的各类别高置信度和背景高置信度区域进行采样,得到多个正对和负对(实际上是在多个小范围内进行采样,如果采样到中性区域则忽略,采样到人和植物或人和背景则认为是负对,如果是人和人则为正对),需要注意的是在训练期间其实只使用足够相邻的坐标(一定半径范围内进行采样),文章中的解释为:由于以下两个原因,在训练期间仅考虑足够相邻坐标的亲和力。首先,由于缺乏上下文,很难预测两个相距太远的坐标之间的语义相似性。其次,通过仅寻址相邻坐标对,我们可以显着降低计算成本。
采样的坐标对(pair)表示为
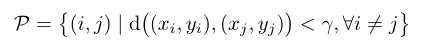
由于正负样本不平衡的问题,直接从P中进行学习是不可取的,因为负对仅在对象边界周围采样得到,所以类分布显著偏向正分布,同时在正对的子集中,由于在许多图像中背景大于对象区域,背景对的数量会明显大于对象对的数量,为解决这一问题,将P分为三个子集,分开计算。首先将P分为正子集和负子集:
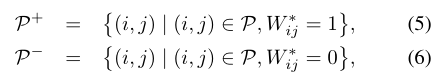
然后将正子集划分为前景$P^{+}_{fg}$和背景 $P^{+}_{bg}$两个子集,然后在三个子集上分别计算CE loss,然后加权相加得到最终的loss:
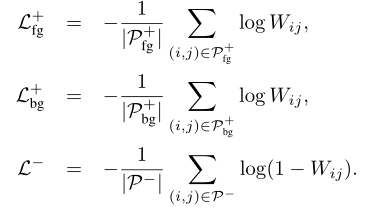
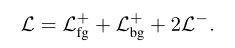
需要注意的是,这一损失是与类别无关的,知识决定了两个相邻坐标之间的类一致性,并不知道具体的类。
随机游走扩散语义区域
从AffinityNet预测的特征图计算得到亲和力矩阵,其对角元素为1,随机游走使用的语义转移概率矩阵T由亲和力矩阵得到:

$\beta$是一个大于1的超参数,这个参数越大则概率转移矩阵中的概率越小,换言之,在随机游走传播时将更加保守,上式中的D是一个对角矩阵,用于对W进行逐行的normalization,也就是每行的概率和为1。在做归一化前,每行的和是大于1的,因为每行都由一个1和若干个大于等于0的数组成。
随机游走的单次操作通过将T和展平的CAM相乘来实现:
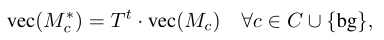
也就是更新后的CAM上的每一位置是根据原本的CAM每一位置的值加权求和得到的,权值就是当前位置像素和所有像素的亲和力
(个人理解:感觉和局部一致性的模块的做法相似,只是使用的特征不一样(RGBxy和亲和力),计算的范围不一样(局部和全局))
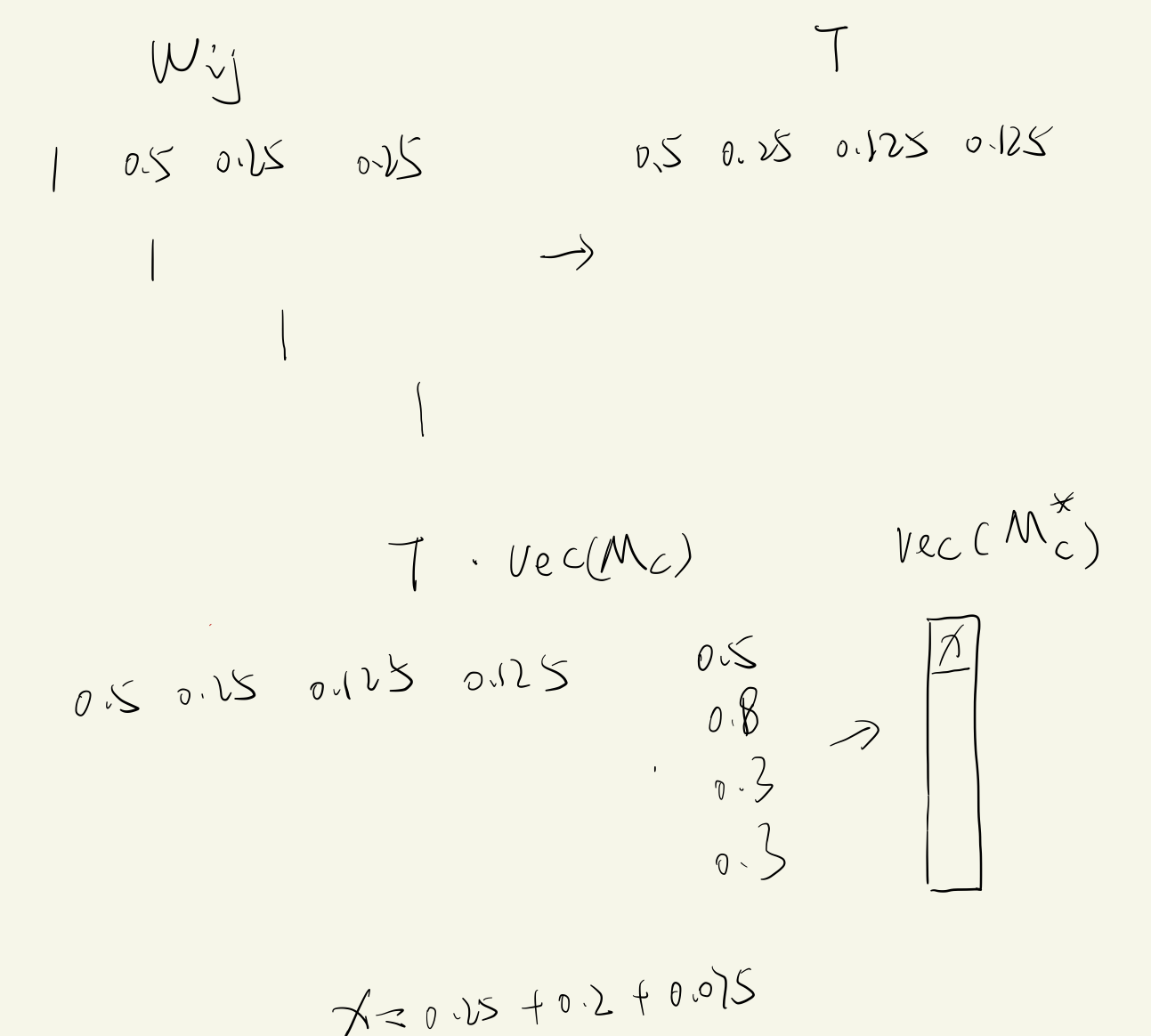
训练分割网络
将随机游走修改后的CAM通过双线性插值上采样到原图分辨率,然后使用dCRF进行细化,然后选择每个像素处最大激活分数的类作为类标签,获得图像的分割标签。
通过检测特征图$f_{aff}$上的边缘来可视化预测的图像语义亲和力,并观察到 AffinityNet具有检测语义边界的能力,尽管它是使用图像级标签进行训练的。由于这样的边界会惩罚语义不同对象之间的随机游走传播,因此合成的分割标签可以恢复对象的准确形
