CVPR2021 SLT-Net
Strengthen Learning Tolerance for Weakly Supervised Object Localization增强学习容忍度
gt known loc acc 87.6%
WSOL存在的问题
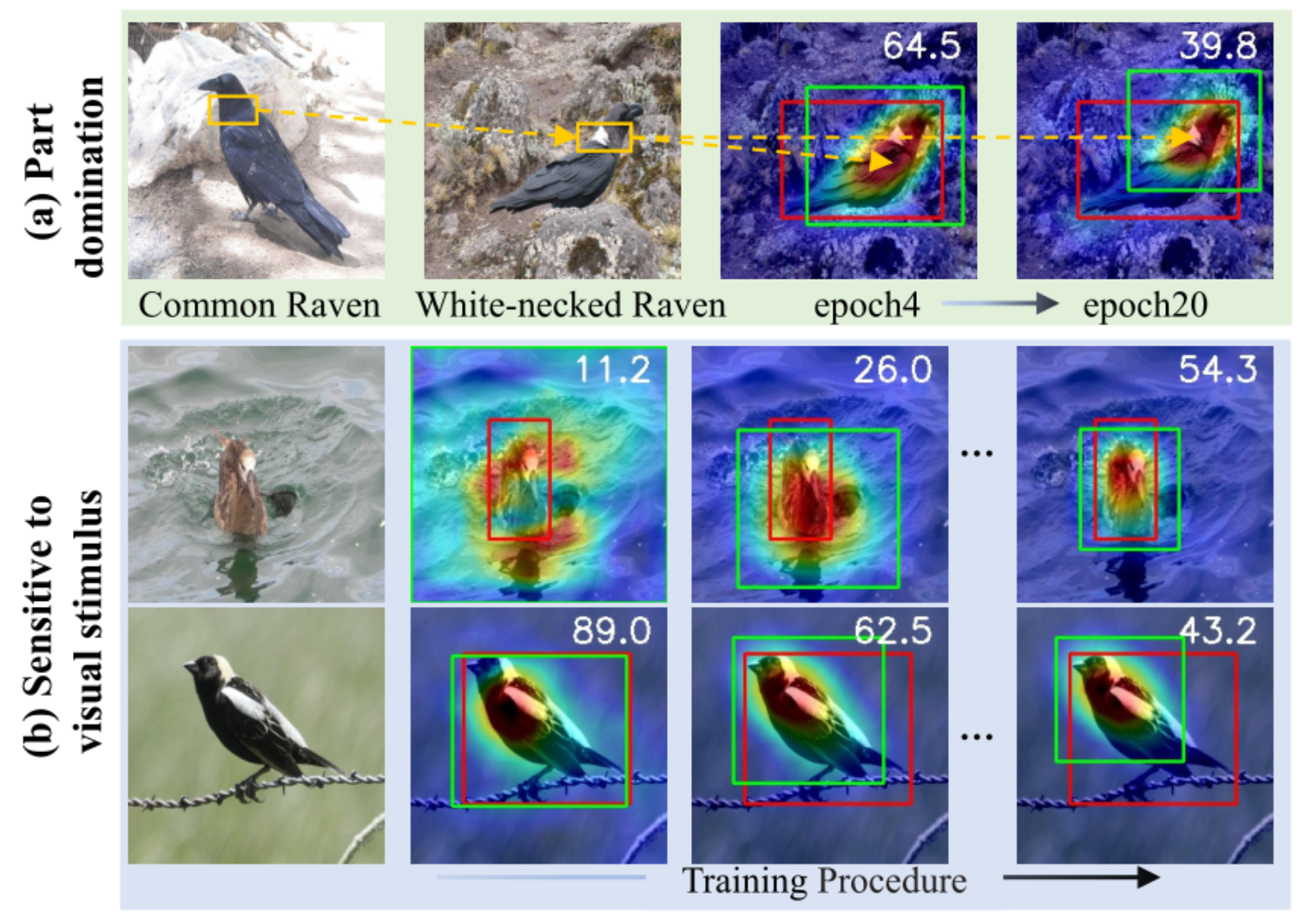
关注最具判别性的区域
由于 Common Raven 类别和 White-necked Raven 类别除了颈部区域的颜色外几乎没有区别,因此从这些图像中提取的类激活图只会关注鸟的颈部,这将导致对物体位置的错误预测。我们认为,造成这种现象的原因是对语义错误缺乏容忍度
解决方法(Tolerance to Semantic Mistakes)
减少相似类别之间错误分类的惩罚,缓解这一问题
视觉敏感性:不同实例的定位精度表现出不同的收敛趋势。(可以理解为鲁棒性不强)
虽然只有图像级监督可用,但该模型在学习过程中几乎无法提取等变模式。这使得模型对输入视觉刺激的变化敏感,例如不同的色调、对比度、纹理、空间位置等。因此,不同实例的定位精度的收敛趋势变得非常不同。这种现象使得很难获得可以对任意输入图像实现准确性能的 WSOL 模型。
解决方法(Tolerance to Visual Stimulus)
变换图像的视觉响应图与原始图像的视觉响应图相匹配来增强对图像多样性的容忍度。
WSOL的两类方法
定位、分类统一框架:
Grad-cam, HaS, ACoL, SPG, ADL, Danet, EIL, CutMix
定位、分类分离框架:
PSOL, GC-net以及本文提出的SLT-Net
SLT-Net
总体框架
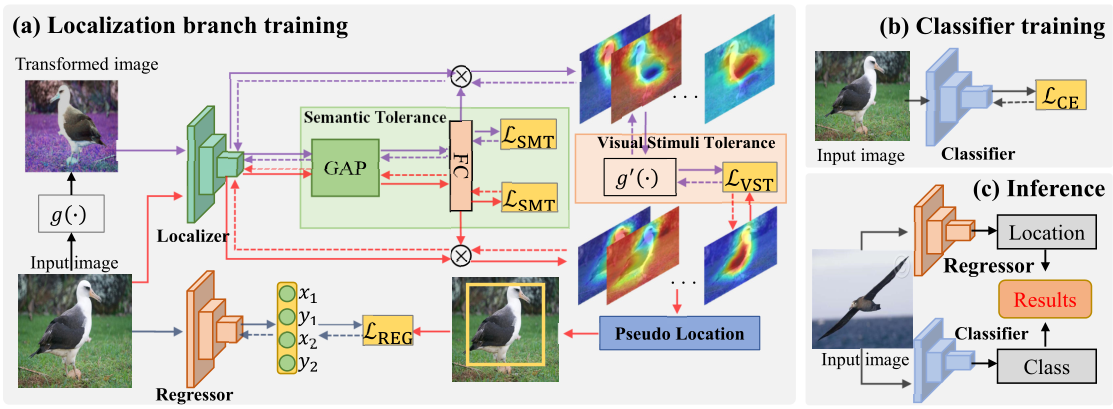
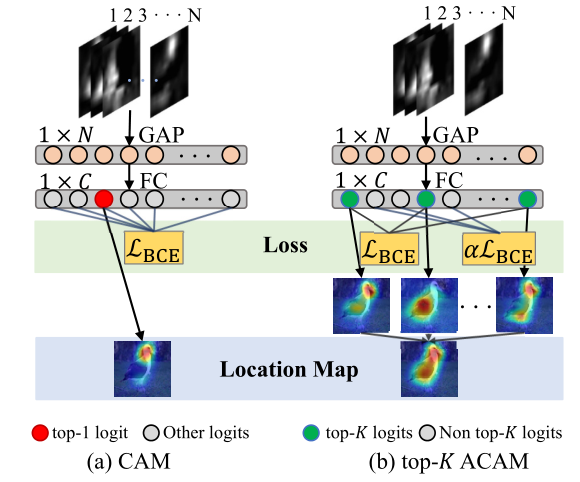
语义错误容忍模块(SMT)
semantic mistakes tolerance module (SMT)
当预测结果中top-k包含gt时,减少其损失值(采用交叉熵,添加衰减系数)
视觉刺激容忍模块(VST)
visual stimulus tolerance module(VST)
对原图像进行图像变换,包括颜色抖动(包括亮度、对比度、饱和度和色调)、水平翻转、缩放。
将原图像和变换后图像输入定位器得到两个类激活图,将变换后图像对应的类激活图做空间变换的逆变换,转换为与原图像一致的空间。原图像类激活图和逆变换后的变换图像类激活图应相似,使用均方差作为损失函数。