CVPR2020 全卷积网络超像素分割
Superpixel Segmentation with Fully Convolutional Networks
Abstract
超像素通过将感知上相似的像素组合在一起来提供图像数据的紧凑表示。作为一种有效减少后续处理图像基元数量的方法,超像素已被广泛应用于视觉问题。但是只有少数尝试将它们整合到深度神经网络中。一个主要原因是标准卷积操作是在规则网格上定义的,并且在应用于超像素时变得低效。
Introduction
修改深度架构以合并超像素的相关文章:
Superpixel convolutional networks using bilateral inceptions. ECCV 2016
Supercnn: A superpixelwise convolutional neural network for salient object detection. IJCV 2015.
- Weakly supervised semantic segmentation using superpixel pooling network. AAAI 2017
- Superpixel convolution for segmentation. ICIP 2018
- Superpixel sampling networks. ECCV 2018.
本文提到的关键思想:将每个超像素和常规图像的网格单元相关联,这是传统超像素算法初始化的常用策略,将超像素分割任务看作找到图像像素和常规网格单元之间的关联分数,并使用全卷积网络直接预测分数。
本文主要贡献:
提出了一个简单的全卷积网络用于超像素分割
提出了一个通用的基于超像素的下采样/上采样框架
与下游任务一起训练超像素
Related Work
- Superpixel segmentation
- The use of superpixels in deep neural networks
- Stereo matching 立体匹配
Superpixel Segmentation Method 超像素分割方法
从规则网格中学习超像素
进行超像素分割的常用策略是首先使用大小为 h × w 的规则网格对 H × W 图像进行分割,并考虑每个网格单元作为初始超像素seed。
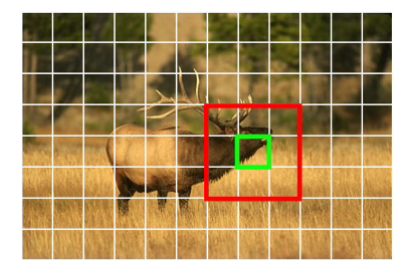
然后通过找到一个映射来获得最终的超像素分割,这个映射将每个像素 $p=(u,v)$分配给seeds $ s=(i,j)$之一。映射可以表示为:若第$ (u,v)$个像素属于第$ (i,j)$个超像素,则$g_s(p)=g_{i,j}(u,v)=1$,否则为0。实际情况中,计算所有的像素-超像素对的计算量非常大,所以将搜索范围限制在周围$N_p$个网格中,如图对于绿色框中的每个像素只考虑将其分配给红色框中的9个网格单元。
最后的映射的张量形式为$G \in Z^{H \times W \times |N_p|}$,其中 $ N_p=9$。值为0或1,称为硬关联(hard assignment),但为了使目标函数可微,将硬关联替换为软关联(soft association map)$Q \in R^{H \times W \times |N_p|}$,也就是预测每个像素属于领域超像素s的概率分布,和为1,最后通过将每个像素分配给概率最高的网格单元来获得超像素:$s^*=argmax_sq_s(p)$。
与SSN的区别
SSN是一种用于超像素分割的端到端可训练深度网络。与本论文的方法类似,SSN 也计算软关联图 Q。然而,不同的是,SSN 使用 CNN 作为提取像素特征的手段,然后将其馈送到软 K-means 聚类模块以计算 Q,本文则是将特征提取和超像素分割合并为一个步骤。因此,SEN的网络运行速度更快,并且可以轻松集成到现有的 CNN 框架中以执行下游任务。

网络设计和损失函数
网络结构
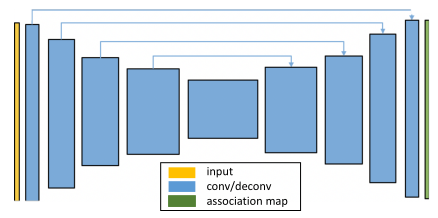
端到端可训练超像素网络的主要优势之一是它的灵活性。超像素将相似的像素组合在一起。对于不同的应用,人们可能希望以不同的方式定义相似性。
将我们希望超像素保留的像素属性表示为 $f(p)$ ,包括 3 维 CIELAB 颜色向量和/或语义标签的 N 维 one-hot 编码向量,其中 N 是类的数量,用图像坐标表示像素位置$ p=[x, y]^T$。
超像素中心的计算方法
超像素s的中心表示为$c_s = (u_s,l_s)$ ,$ u_s$表示属性向量(property vector),表示的是分配给s超像素的所有像素的属性平均特征。$ l_s$位置向量(location vector),表示超像素s的位置中心。利用得到的预测软关联图$Q$进行计算,$q_s(p)$表示p像素属于s超像素的概率,$ f(p)$表示像素p的属性。
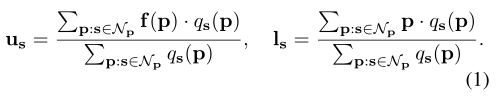
重建像素p的属性向量和位置向量,可以从9个超像素中心重建出像素的特征
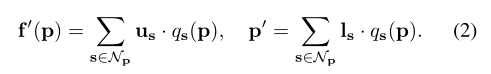
损失函数
第一项鼓励训练模型对具有相似感兴趣属性的像素进行分组,重建出来的像素属性要和原本属性相近,从式2可以看出来需要超像素的中心与像素接近,分配的概率大,重建出来的属性就越接近原本属性。
第二项强制超像素在空间上紧凑,也就是像素本身的位置离超像素中心越近越好(如果预测出分配给的超像素离像素原本位置越远,则重建像素p的位置向量得到的$p^,$),加了个系数,m/S,m为权值系数,S为超像素个数
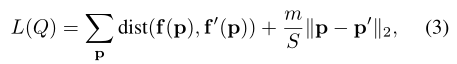
对于像素属性$f(p)$,在本文中考虑了两种方案:
CIELAB color vector使用l2距离
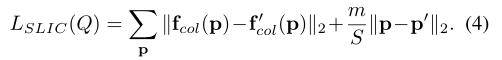
one-hot encoding vector of semantic labels使用cross-entropy优化
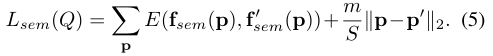
与CSP network连接
待看
基于超像素的上下采样
下采样其实就是基于公式1,下采样后的图实际上就是超像素中心图,也就是H×W×3的输入图像变为了i×j×c
上采样基于公式2