基于深度特征的无监督图像检索研究综述
content-based image retrieval, CBIR
基于内容的图像检索CBIR,给定一个查询图像,从数据库图像中找到包含相同实例的图像,需要解决类内差异。
典型的图像检索流程包括2步:
- 从图像中提取一个图像的表示向量
- 对表示向量用欧氏距离或余弦距离进行最近邻搜索以找到相似图像
决定一个图像检索算法性能的关键在于提取的图像表示的好坏
常用指标
mAP 平均准确率均值 mean average precision
对每张查询图像,根据查询图像和数据库图像的表示向量间的距离,可以对数据库图像产生一个排序,,画出对该查询图像的查准率-查全率(P-R)曲线,平均准确率AP就对应P-R曲线下的面积,对所有查询图像的AP做平均,即可得到mAP,值是0%-100%。
基于深度全局特征的图像检索
深度神经网络的全连接层特征提供了对图像内容高层级的描述,一些早期工作直接将整张图像输入预训练好的网络,并提取深度全连接特征作为图像的表示向量,这种深度全连接特征的实质时对图像整体语义信息进行描述的深度全局特征。
为了得到更精简的图像表示,可以用PCA对从深度全连接特征提取的图像表示进行降维(如4096维降到128)
由于预训练数据集和用于图像检索的数据集差异的存在,文献发现略低层的特征有更好的检索效果,这是因为非常高层的深度特征旨在进行预训练数据集的分类任务,而略低层的深度特征有更好的对其他数据集的泛化能力。
总结:
使用深度全局特征作为图像表示十分简单直接,但全局特征旨在进行图像分类,缺乏对图像细节的描述,此外深度全局特征对图像平移、旋转、尺度缩放比较敏感
基于深度局部特征的图像检索
局部表示聚合
受经典 SIFT特征和 BoW聚合思路的启发,一些工作用深度特征代替经典SIFT特征,并对经典编码技术如BoW , VLAD,FV 等加以改进.这类方法先设法从输入图像中提取一系列的局部区域,之后分别将这些图像局部区域前馈网络﹐并生成对应的局部图像表示.最后,通过特定聚合方法将这些局部图像表示聚合为最终图像表示。也就是用多个局部特征融合成图像表示。
这类方法的关键是如何从输入图像提取局部区域,如何对局部表示进行聚合。提取局部区域的方法主要有3类:基于滑动窗的局部区域提取、兴趣区域检测和基于候选区域(region proposal)的局部区域提取.
为了精确找到有价值的局部区域,基于滑动窗的方法需要用一系列不同大小的滑动窗口,这需要消耗不小的计算开销.而基于兴趣区域检测和基于候选区域的方法由于只需提取一部分局部区域前馈网络,因此效率相比较高.基于兴趣区域检测的方法沿用了经典图像检索/计算机视觉的特征提取思路,而基于候选区域的方法受到目标检测任务做法的启发.但这些方法都需要多次前馈网络.
深度卷积特征聚合
相比深度全局特征(全连接层的一维向量),深度卷积特征(可以理解为DxHxW的特征图)对图像的平移、裁剪、遮挡更不敏感,并保留了更多图像细节信息。相比局部表示聚合的方法,基于深度卷积特征融合的方法只需要前向传播一次,而且可以处理任意大小的图像输入。这类方法关键在于如何对深度卷积特征进行聚合,直接聚合的方法空间全局最大池化,和池化,平均池化等方式,得到一个D维的特征向量,加权聚合这类方法是在聚合时根据不同位置的特征的重要性对深度卷积特征进行加权求和,得到一个D维向量,然后再对D维的D个通道进行加权
- Class-weighted convolutional feature
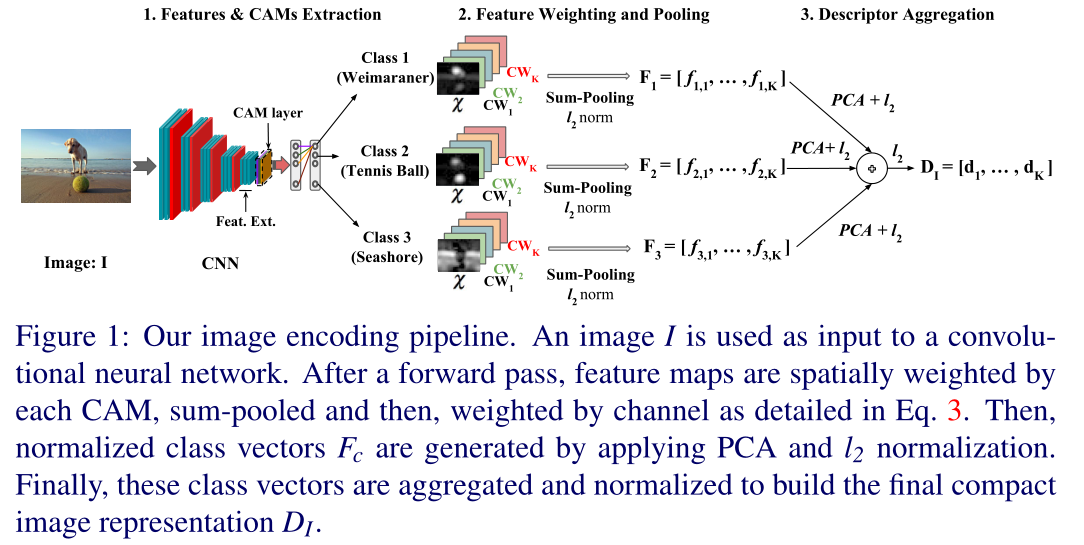
SUM Pooling
基于 SUM pooling 的中层特征表示方法,指的是针对中间层的任意一个 channel(比如 VGGNet16, pool5 有 512 个 channel),将该 channel 的 feature map 的所有像素值求和,这样每一个 channel 得到一个实数值,N 个 channel 最终会得到一个长度为 N 的向量,该向量即为 SUM pooling 的结果。
AVE pooling
AVE pooling 就是 average pooling,本质上它跟 SUM pooling 是一样的,只不过是将像素值求和后还除以了 feature map 的尺寸。作者以为,AVE pooling 可以带来一定意义上的平滑,可以减小图像尺寸变化的干扰。设想一张 224224 的图像,将其 resize 到 448448 后,分别采用 SUM pooling 和 AVE pooling 对这两张图像提取特征,我们猜测的结果是,SUM pooling 计算出来的余弦相似度相比于 AVE pooling 算出来的应该更小,也就是 AVE pooling 应该稍微优于 SUM pooling 一些。
多层融合
深度特征具有层次性,从低层到高层是由纹理特征到高层语义特征的转变,深度加深,感受野变大,更倾向于捕获全局语义特征,不同层特征的感受野不同,多层特征融合可以同时捕获不同尺度下的图像语义信息。各层的权重不应该相同
实现细节
- 在ImageNet预训练
- VGGNet
- 使用原图大小输入,保持原图长宽比
- 使用经过ReLU之后的深度特征
- 使用sum pooling会比max pooling更好,sum-pooling再除以feature map的尺寸就是ave pooling(CAM的GAP)
- 对提取到的图像表示(特征向量)进行l2规范化,PCA白化(用于应对特征向量各维之间的共现co-occurrence效应,并对高维的表示向量进行降维),然后进行再次l2规范化(为了使表示向量的空间由欧式空间映射到余弦空间)

- 从另一个独立的数据集学习PCA的参数
- 幂律规范化
- 对检索得到的排序进行后处理,对排序结果进行微调,如查询展开:将排序最前面的k个结果的特征向量(表示向量)sum pooling并进行l2规范化,将结果作为新的查询向量重新进行检索。空间重排: