ICCV2021 TS-CAM
TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization
Motivation&background
作者认为部分激活是由 CNN 的内在特性引起的,其中卷积操作会产生局部感受野,并且难以捕捉像素之间的远程特征依赖关系。所以提出利用self-attention机制的长程建模能力来避免局部激活问题。TS-CAM首先将一张图像分割成一系列用于spatial embedding的patch token,它们将产生long-range的视觉关联性的attention map去避免局部激活现象。然后TS-CAM为每个patch tokens重新分配与种类有关的语义种类,使它们能够了解对象类别,TS-CAM最终将patch token与语义不可知的attention map耦合,以实现语义感知定位。
vision transformer应用于WSOL还存在的问题:
- patch embeddings实际上破坏了输入图像的空间拓扑结构,这阻碍了目标定位激活图的生成
- vision transformer的注意力图与语义无关(无法区分对象类)并且不适合语义感知定位semantic-aware localization
Related Work
WSOL
作者提到大多数方法都通过将复杂的空间正则化技术引入 CAM 来扩展激活区域。然而,他们难以解决图像分类和目标定位两个任务之间的矛盾。
WSOD&WSSS
Long-Range Feature Dependency
Methodology
TS-CAM引入了一种具有两个网络分支的语义耦合结构,如下图所示。一个使用patch tokens执行语义重新分配,另一个在 class tokens上生成语义不可知的attention-map。语义的重新分配,通过class-patch语义的激活,使 patch tokens能够感知对象类别。语义不可知的attention map旨在利用transformer中级联的self-attention modules的优势,捕获patch tokens之间的长程特征依赖。TS-CAM最终将语义感知图与语义不可知注意图耦合,用于目标定位。
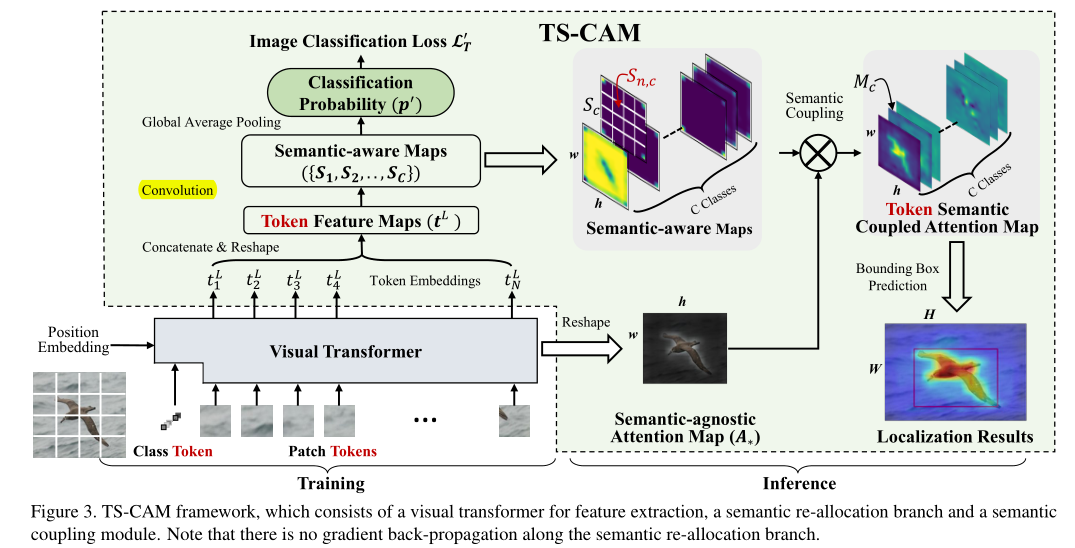
与vit中一致,先将输入图像分割成N个PxP的patch,代码中P=16,输入图像尺寸为224,也就是切割成N=14x14=196个尺寸为16x16的patch,然后被展平输入卷积进行线性投影得到N=196个patch token,每个token用一个192维的向量表示。输入x的shape为[bs,3,224,224],经过patch embbeding后变为[16,196,192]。然后经过与cls_token的拼接和position encoding得到图中的Token Embeddings( $t_{1}^{L}$到 $t_{N}^{L}$)以及cls_token $t_{*}^{L}$。经过L层transformer block得到最终的tokens。
以上的操作都与vit一致,但是在vision transformer中,只有cls_token是和语义有关的,其他token都是语义无关的,TS-CAM中使用两个分支分别解决语义感知的问题和定位问题。
Semantic Re-allocation
Visual Transformer使用class token预测图像类别(语义),同时使用语义不可知的patch tokens嵌入对象空间位置并反映特征空间依赖性。为了生成语义可知的patch token,作者将语义从cls_token重新分配到其他patch token。看一下代码实现细节。
1 | # deit文件中的forward,bs=16,以tiny为例 |
总结起来,就是将原本的token还原成原本的空间排列也就是文中指的token feature map即 $t^L\in R^{D\times w\times h}$,在上述的代码分析中就是192x14x14. semantic aware map $S_c$是通过对token feature map进行卷积得到,也就是代码中的x_patch = self.head(x_patch),文中的公式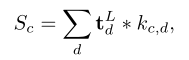 中的c就是指self.num_classes,d指self.embed_dim,也就是对token feature map(192,14,14)进行卷积得到了semantic aware map $S_c$(200,14,14),每个类都有一张14x14的得分图,代表对应位置patch是这个类的可能性得分。
中的c就是指self.num_classes,d指self.embed_dim,也就是对token feature map(192,14,14)进行卷积得到了semantic aware map $S_c$(200,14,14),每个类都有一张14x14的得分图,代表对应位置patch是这个类的可能性得分。
在得到了semantic aware map后,计算loss function
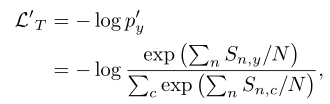
其实就是对semantic aware map进行GAP(14x14 -> 1)操作,然后softmax计算概率分布,然后crossentropy计算损失。
到这里,可以发现,cls_token都还没有被使用过,原本的vit中cls_token会被用来计算最后的loss
Semantic-agnostic Attention Map & Semantic-Attention Coupling
代码中的均值操作就是文中所指的 $ A_{*}^{l}$ 被更新为来自k=3个head的attention vector的均值, 通过矩阵乘法运算记录 class token对所有 tokens 的依赖关系。只不过是在最后才取出cls_token的attention vector,然后reshape成原本的token空间分布,如14x14。需要注意的是这个attention map是语义无关的,所以最后和前面的得到的semantic aware map相乘,得到最后的类激活图。
1 | # attn_weights是一个长度为12的list,12是transformer block的个数 ,每个元素是每层的注意力分布矩阵[16,3,197,197] |
Experiments

TransAttention 仅利用 Transformer 结构中的注意力图,突出了大部分对象部分,但由于缺乏类别语义,无法精确定位完整对象。TS-CAM 保留全局结构并覆盖更多范围的对象,可以把最后的耦合过程理解成,利用语义图对前景图的每个patch进行修正,和当前类相关的patch的值被放大,无关的patch值被抑制。

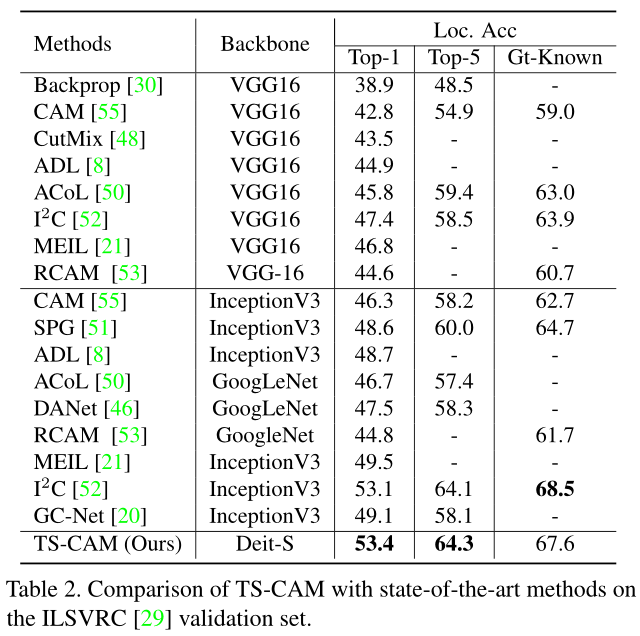
Results
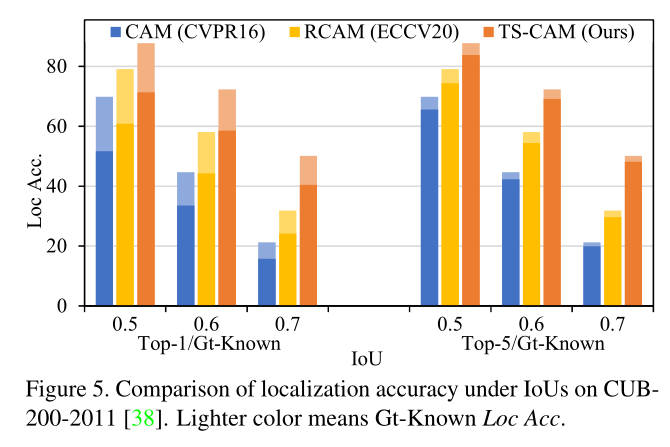
- 随着 IoU 阈值的增加,TS-CAM 获得了更大的增益,这表明TS-CAM方法的定位图准确地覆盖了目标范围
- 五类定位误差的分析:

- 文章中采用summarize all attention maps的原因,如图分析,从不同层得到的 $A_{*}^{l}$(从class token得到的attention vector),求和的定位精度最高。
