ICLR2021 Vision Transformer(ViT)
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
整体架构
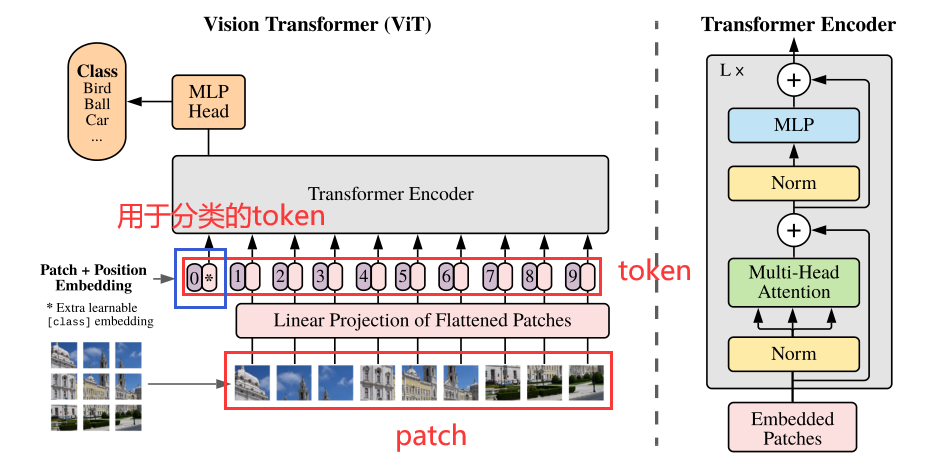
Method
首先将图像分割成$N=HW/P^2$个2D的patch(图像块),每个patch的分辨率是$P\times P$
使用线性映射将patch展平得到D维的patch embedding,并加上cls_token(全0初始化)
1
2
3
4
5
6
7
8
9
10self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=patch_size,
stride=patch_size)
# 比如要对16x16的patch做embedding为D=768维的向量,则使用Conv2d(3,768,16,16)
# 卷积后的结果shape为(bs,768,H/16,W/16)
# 然后进行flatten操作,并调整维度为(bs,N,768)
# 最后把cls_token与图像的patch embedding拼接维度变为(bs,N+1,768)
# 其中cls_token的初始化为
self.cls_token = nn.Parameter(torch.zeros(bs, 1, config.hidden_size))对patch embeddings进行1D的position embedding(位置编码)得到tokens
1
2self.position_embeddings = nn.Parameter(torch.zeros(1, N+1, config.hidden_size))
embeddings = x + self.position_embeddings # x是(bs,N+1,768),position_embedding是(1,N+1,768)送入transformer encoder
transformer encoder由multiheaded self-attention block(MSA)和 MLP blocks交替组成,在输入每个block前都会先进行Layernorm (LN),在每个block之后都会进行残差连接
- MSA的构建
1
2
3
4
5
6
7self.attention_head_size = int(config.hidden_size / self.num_attention_heads) # 64=768/12
self.all_head_size = self.num_attention_heads * self.attention_head_size #768 = 12*64
# 使用全连接层构建QKV,一次性把所有头的QKV构建
self.query = Linear(config.hidden_size, self.all_head_size)
self.key = Linear(config.hidden_size, self.all_head_size)
self.value = Linear(config.hidden_size, self.all_head_size)
#通过reshape和permute得到多头结果,然后做self-attention,用softmax得到的概率分布乘上输入,完成特征的重构- MLP的构建
2个Linear和GELU
1
2
3
4
5
6
7def forward(self, x):
x = self.fc1(x) # Linear(config.hidden_size, config.transformer["mlp_dim"])
x = self.act_fn(x) # GELU
x = self.dropout(x)
x = self.fc2(x) # Linear(config.transformer["mlp_dim"], config.hidden_size)
x = self.dropout(x)
return x利用cls_token进行分类
1
2self.head = Linear(config.hidden_size, num_classes)
logits = self.head(x[:, 0]) # x的shape[bs, N+1, 768],取每张图片的第0个token,也就是cls_token,送进全连接进行分类Attention(以dino_deitsmall16_pretrain.pth为例)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
# dim = 384, num_heads = 6
self.num_heads = num_heads
# head_dim = 384/6 = 64
head_dim = dim // num_heads
# 64**-0.5=0.125
self.scale = qk_scale or head_dim ** -0.5
# Linear(in_features=384, out_features=1152, bias=True)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
# attn_drop = 0,未使用dropout
self.attn_drop = nn.Dropout(attn_drop)
# Linear(in_features=384, out_features=384, bias=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
# [1,197,384]
B, N, C = x.shape
# self.qkv(x) [1,197,1152]
# 1152分为q,k,v三个部分每个部分384,每个384又是由多头组成,这里头数量为6,所以每个头的特征维度为64
# reshape [1, 197, 3, 6, 64]
# permute [3, 1, 6, 197, 64],含义是qkv三个输出,6个头,每个头对197个token的特征用64维的向量表示
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# qkv均为[1, 6, 197, 64]
q, k, v = qkv[0], qkv[1], qkv[2]
# attn [1,6,197,197]
attn = (q @ k.transpose(-2, -1)) * self.scale
# 按行做softmax,行归一化
attn = attn.softmax(dim=-1)
# 对attn进行dropout,按概率将参数置零
attn = self.attn_drop(attn)
# attn @ v [1, 6, 197, 64]
# 重构出x [1,197,384]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
# attn [1,6,197,197]
return x, attn