ICCV2021 DINO
Emerging Properties in Self-Supervised Vision Transformers
Abstract
自监督学习带来的影响:自监督vit特征包含了图像语义分割的明确信息,这在监督学习的vit和CNN中都没有这么清晰
文章将DINO解释为一种没有标签的自蒸馏形式
Introduction
在本文中,作者怀疑Transformers 在视觉方面的成功可能是因为预训练中的监督。这样怀疑的动机是Transformers 在 NLP 中取得成功的主要因素之一是就是使用了自监督的预训练,其形式是 BERT 或 GPT 中的语言建模。这些自监督的预训练目标使用句子中的单词来创建pretext task,这些任务提供比预测每个句子单个标签的监督目标更丰富的学习信号。类似地,在图像中,图像级监督通常将图像中包含的丰富视觉信息减少为从预定义的数千个对象类别中选择的单个概念。
本文研究了自监督预训练对vit特征的影响,发现:
- 自监督的vit特征明确的包含了场景,特别是对象边界
- 自监督vit特征在没有任何微调、线性分类器、数据增强的情况下,k-NN分类器效果非常好,在ImageNet实现78.3% top-1 acc
- vit中使用更小patches带来更好的结果
Related work
- 自监督学习 Self-supervised learning
- 自训练、知识蒸馏 Self-training and knowledge distillation
Approach
DINO的无标签自蒸馏结构
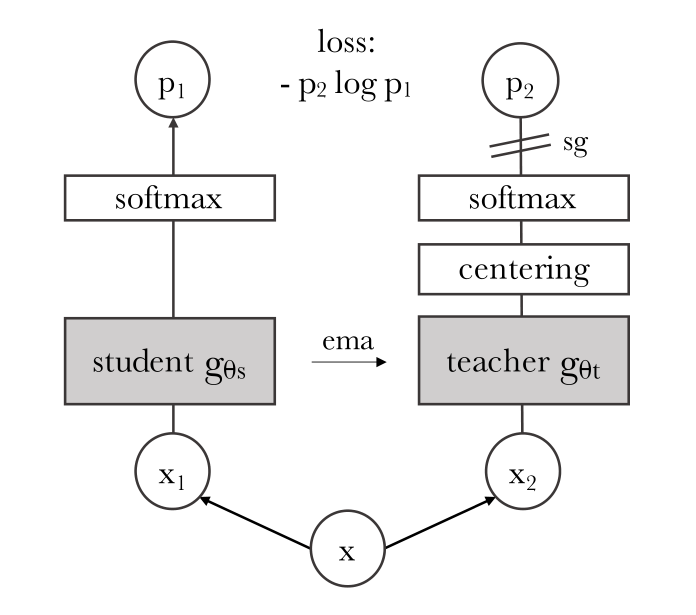
DINO结构中分学生网络和教师网络,两侧网络都使用temperature softmax生成了K维概率分布,student侧为$P_s$(公式1,其中$g_{\theta_s}$代表学生模型输出的logits),teacher侧为$P_t$,然后最小化交叉熵损失来优化student网络的参数$θ_s$(公式2)
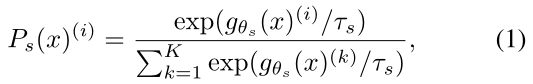
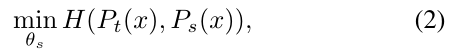
其中$H(a,b)=-alogb$.即结构图中的loss。
DINO中的local-to-global学习
DINO其实在进行交叉熵损失计算时更加复杂,因为使用了多裁剪策略,学生模型的输入是local views($96^2$),教师模型的输入是2张global views($224^2$),所以最终要最小化的损失函数表达式为:
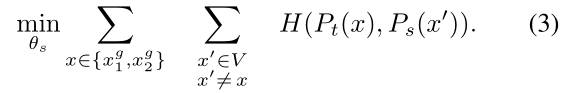
模型参数更新
- 学生模型使用上述的交叉损失进行梯度回传更新参数。
- 教师模型是从学生网络历史iteration中通过EMA(exponential moving average)得到,更新的公式为$θ_{t+1}=\lambda\theta_t+(1-\lambda)\theta_s$,其中在训练阶段$\lambda$遵循从0.996到1余弦变化
网络结构
- backbone:使用ViT或ResNet
- projection head:3层MLP(隐藏层为2048维+$l_2$ normalization+K维的全连接层),在ViT中没有使用BN
避免崩溃
自监督方法避免崩溃的操作有:
- 对比损失
- 聚类约束 clustering constraints
- predictor
- batch normalization
DINO中采用multiple normalizations,具体来说就是使用centering和sharpening操作使通过动量更新的教师模型避免崩溃,减少其对batch的依赖。在实验中发现,centering操作(公式4,$B$代表batch size,m则可以理解为学习率)避免了一个维度主导,但会鼓励塌陷为均匀分布,sharpening(通过teacher模型的softmax函数温度系数$\tau_t$实现)则是相反影响。centering操作和sharpening操作的伪代码可以看出,其实就是中心偏移加温度调节。
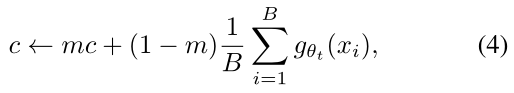

Implementation and evaluation protocols
Vision Transformer 使用DeiT中的实现。
在ImageNet上进行无标签预训练
用k-NN评估特征的质量 (Unsupervised Feature Learning via Non-Parametric Instance Discrimination)
冻结预训练模型,计算并储存下游任务训练数据的特征,然后最近邻分类器将图像特征与k近邻存储的特征匹配,并指定一个label,实验中发现20 NN效果最好,这一评估方式不需要超参数调整也不需要数据增强,只需要通过下游数据集即可运行,简化了特征评估。
Main Results
重点关注图像检索和语义分割部分