知识蒸馏overview
获得高效的深度学习模型的5种方法:
- 手工设计轻量级网络
- 剪枝
- 量化
- 基于神经架构搜索NAS的网络自动化设计
- 知识蒸馏
知识蒸馏的应用:模型压缩,模型增强
- 模型压缩:教师网络在相同的带标签的数据集上指导学生网络的训练来获得简单高效的网络模型
- 模型增强:利用其他资源(如无标签或跨模态数据)或知识蒸馏的优化策略(如相互学习和自学习)来提高一个复杂学生模型的性能
小网络利用大网络的输出知识
softmax的温度系数T(temperature parameter)
②logits通过普通softmax(T=1)得到的是①T=1的类概率,通过T=10的softmax得到③,T的作用是控制输出概率的软化程度,T=1时代表softmax类概率,T为正无穷则表示输出logits。T越小logits经过softmax得到的软目标的差异越大,T越大,差异越小。
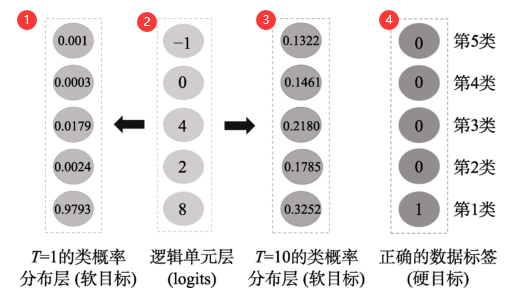
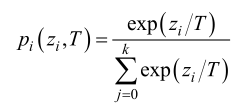
引入T是为了解决把logits和类概率作为知识时产生的问题:
- logits包含噪声,作为监督信号会因过拟合限制学生的泛化能力
- 类概率中的父标签会因softmax变得很小,导致在网络训练时这部分信息丢失
通常,知识蒸馏在测试的时候令T=1,在训练的时候则使用较大的T值.知识蒸馏在测试阶段令T=1时,不同逻辑单元值的软目标的差异很大,所以在测试时能够较好地区分开正确的类和错误的类.而在训练时,较大T值的软目标差异比T=1时的差异小,模型训练时会对较小的逻辑单元给予更多的关注,从而使学生模型学习到这些负样本和正样本之间的关系信息. Hinton等人将这样的蕴含在教师模型中的关系信息称之为“暗知识”(Dark Knowledge),而知识蒸馏就是在训练过程中将教师模型的“暗知识”传递到学生模型中.
大白话说暗知识就是从教师模型中学习到的ground truth中没有的知识,比如两个类的相似性,如果相似,则他们的软目标差异就大概率更小。
在训练时同时使用软目标和硬目标(ground truth)效果更好,也就是对蒸馏损失和学生损失加权求和。
蒸馏损失:具有较高T值的教师模型和较高T值的学生模型的交叉熵损失
学生损失:T=1的学生和ground truth的交叉熵损失
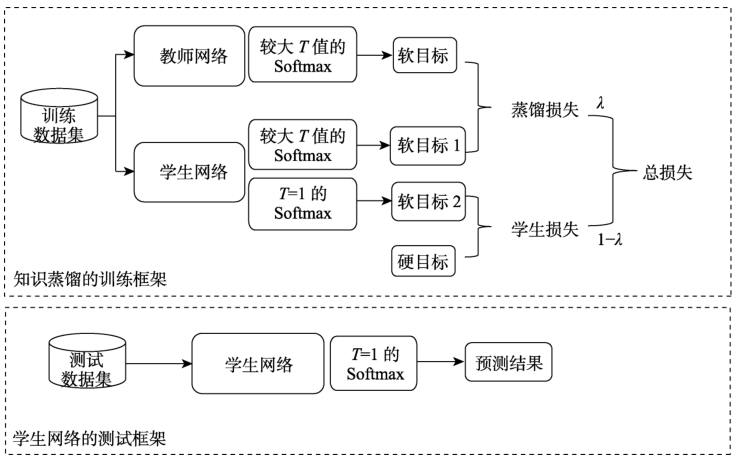
知识蒸馏的作用机理
- 软目标为学生模型提供正则化约束
- 通过标签平滑提供正则化:标签平滑避免了过分相信训练样本的ground truth,防止过拟合
- 通过置信度惩罚提供正则化
- 软目标为学生模型提供特权信息(Privileged Information)。传递暗知识。
- 软目标引导学生模型优化的方向(学习速度更快,性能更优)
蒸馏的知识形式
- 输出特征知识(解题的答案)
- 中间特征知识(解题过程),主要思想是从教师的中间网络层提取特征来充当学生模型中间层输出的提示
- 关系特征知识(解题的方法,学习映射关系),学习的本质不是特征输出的结果,而是层与层之间,样本数据之间的关系,重点是提供一个关系映射,让学生模型学习关系知识(e.g. FSP矩阵)。
- 结构特征知识(提供完整知识体系)
知识蒸馏的方法
- 知识合并(促使学生模型能同时处理多个教师模型原先的任务)
- 多教师学习(提高学生模型在单个任务上的性能)
- 教师助理(减小教师和学生的代沟)
- 跨模态蒸馏(高/低分辨率,视频/语音)
- 相互蒸馏(让一组未经训练的学生模型同时开始学习,共同解决任务,意义是在没有教师模型的情况下,学生模型可以通过相互学习的集成预测提高性能)
- 终身蒸馏(使用知识蒸馏 的方式实现终身学习,解决灾难性遗忘问题(学习新任务时,对旧任务的性能下降))
- 自蒸馏(单个网络,既是教师又是学生,主要有两类,1.使用不同样本信息相互蒸馏,减小类内距离 2.单个网络的网络层间进行自蒸馏,如使用深层网络特征指导浅层网络的学习)**