
Currently, I’m a PhD student at the University of Hong Kong (HKU), advised by Prof. Hongyang Li and Prof. Ping Luo. My research interests include Humanoid Whole-body Control, Human Pose Estimation and Human-Object Interaction.
Towards general-purpose robots — by unifying perception, control, and manipulation through scalable learning.
🔥 News
- 2026.02: 🎉🎉 AMS is accepted by ICRA 2026.
📝 Publications

Agility Meets Stability: Versatile Humanoid Control with Heterogeneous Data
Yixuan Pan*, Ruoyi Qiao*, Li Chen, Kashyap Chitta, Liang Pan, Haoguang Mai, Qingwen Bu, Cunyuan Zheng, Hao Zhao, Ping Luo, Hongyang Li
IEEE International Conference on Robotics and Automation (ICRA 2026), first author
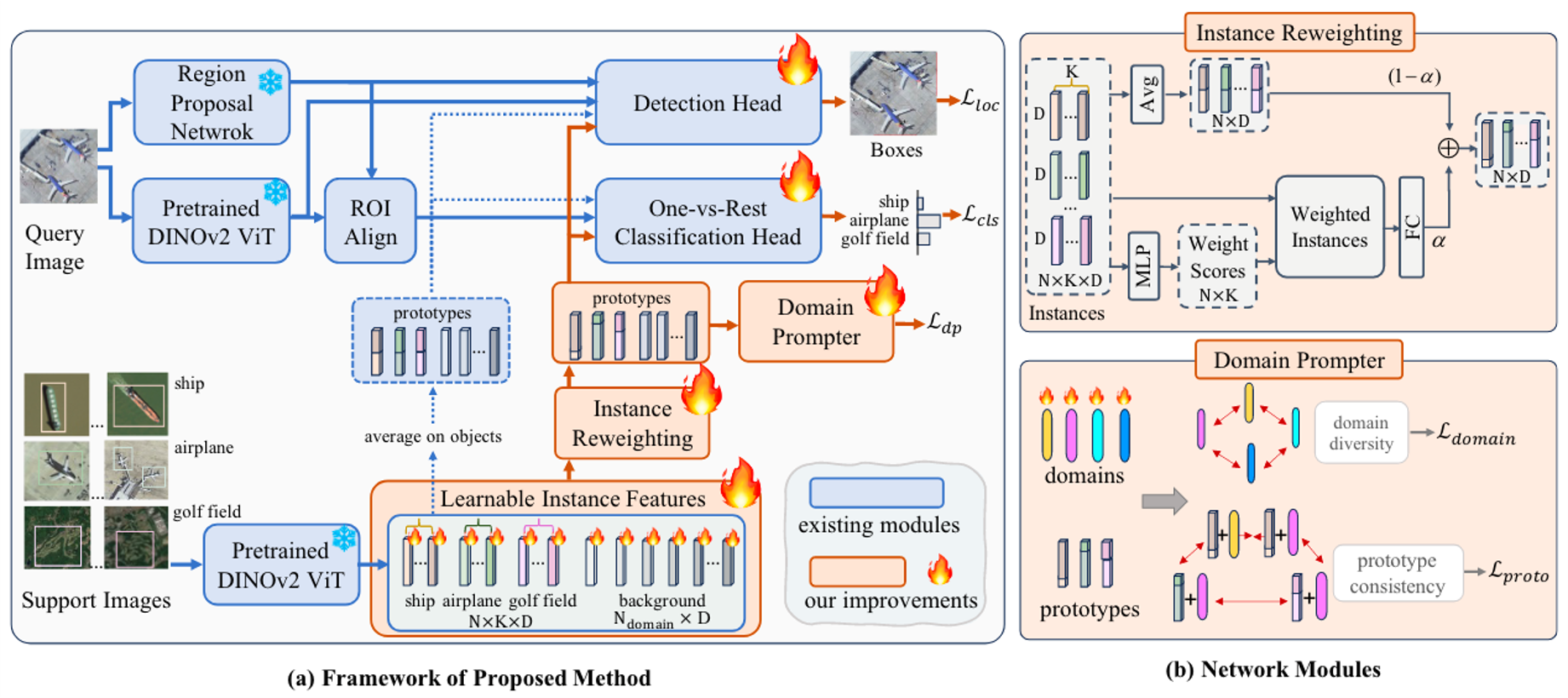
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Yuqian Fu*, Yu Wang*, Yixuan Pan*, Lian Huai, Xingyu Qiu, Tong Liu, Yanwei Fu, Luc Van Gool, Xingqun Jiang
European Conference on Computer Vision (ECCV 2024), co-first author
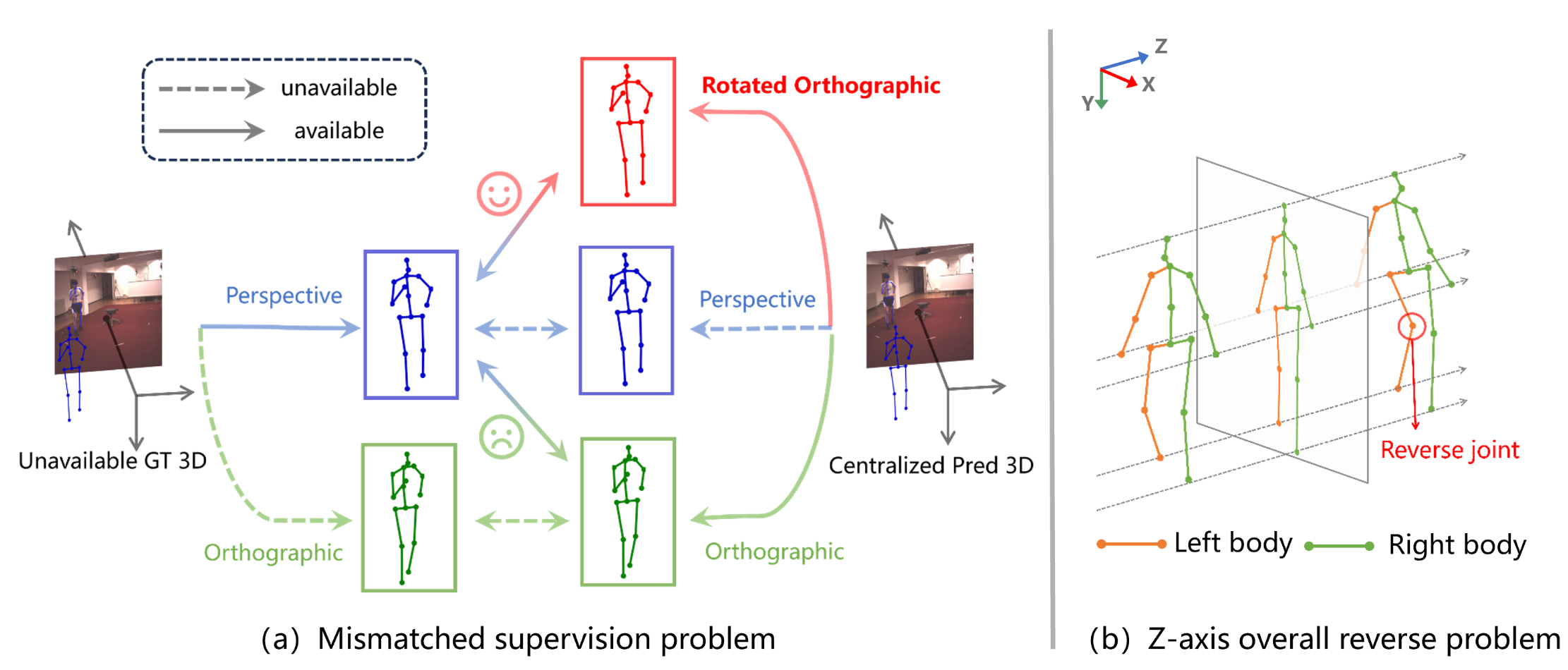
Rotated Orthographic Projection for Self-Supervised 3D Human Pose Estimation
Yao Yao, Yixuan Pan, Wenjun Shi, Dongchen Zhu, Lei Wang, Jiamao Li
European Conference on Computer Vision (ECCV 2024), second author
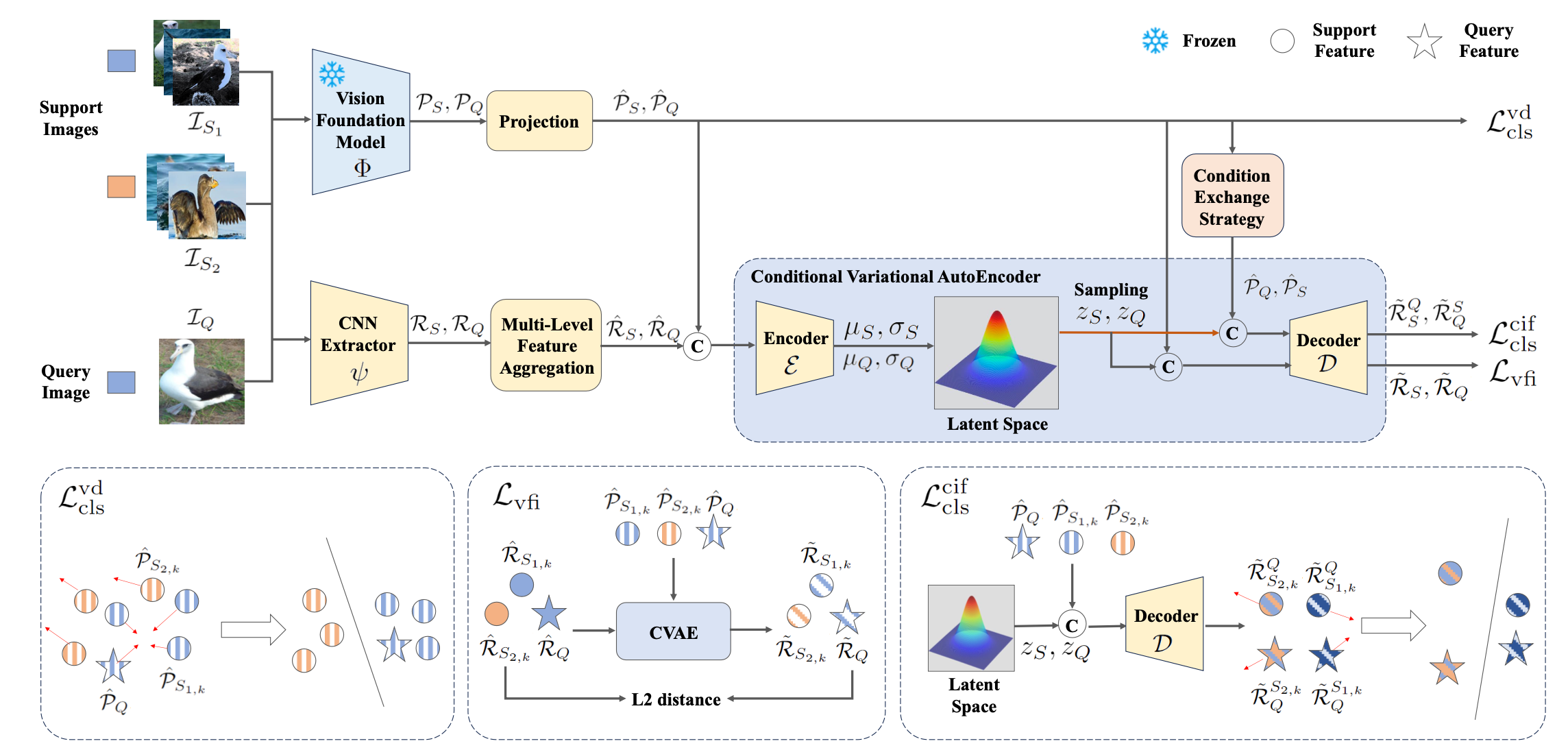
Xin Lu, Yixuan Pan, Yichao Cao, Xin Zhou, and Xiaobo Lu
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), second author
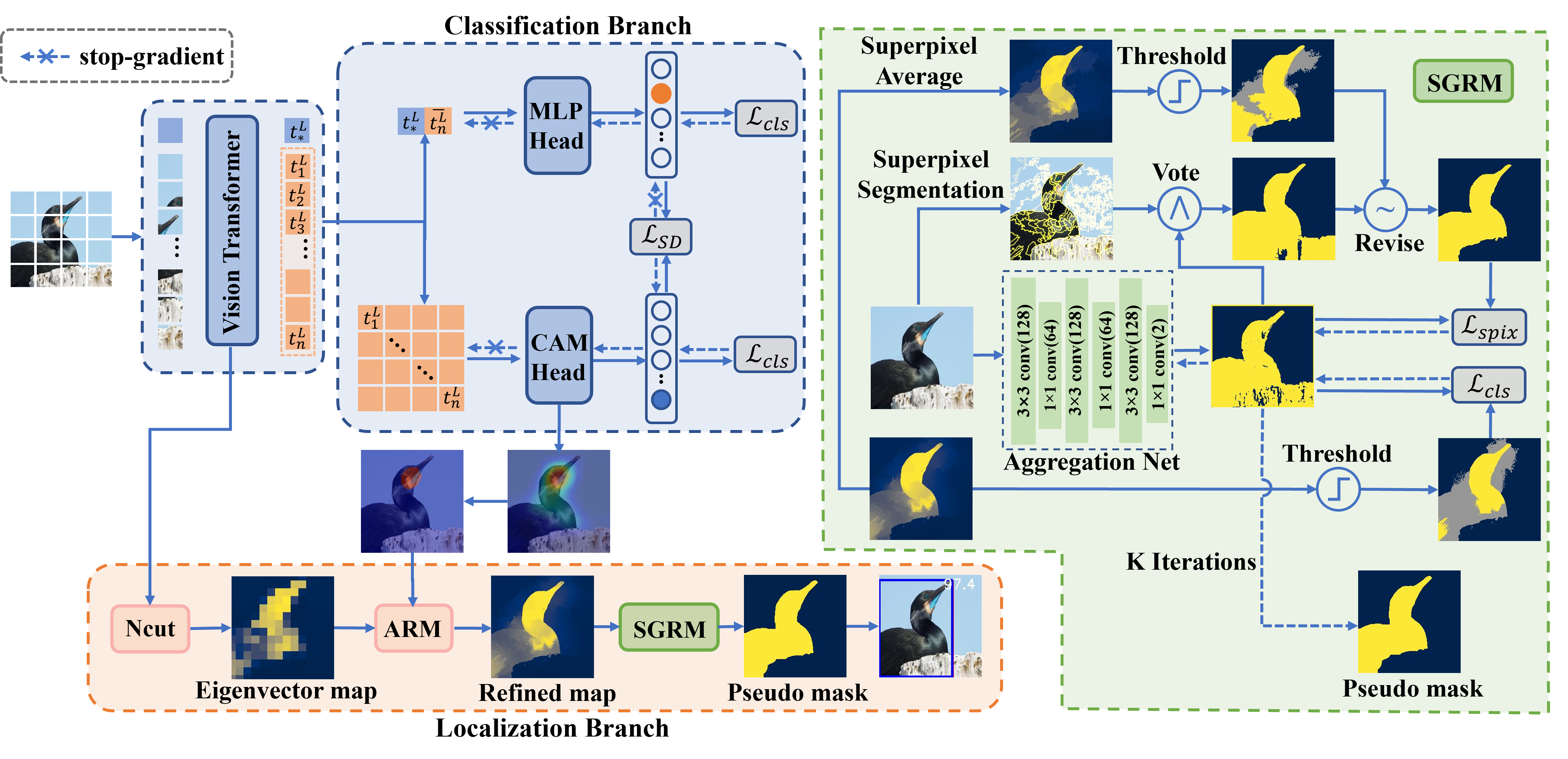
Coarse2Fine: Local Consistency Aware Re-prediction for Weakly Supervised Object Localization
Yixuan Pan, Yao Yao, Yichao Cao, Chongjin Chen, Xiaobo Lu
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2023, oral), first author
🔧 Projects

Simulation of electromagnetic bending gun
Automatic mark finding by camera and precise targeting
National First Prize of National Student Electronic Design Competition (Top 1.8%, total 17,313 teams)

Indoor positioning and tracking of robots
High-precision indoor positioning and tracking based on UWB
Authorized Patent: An EKF-based multi-sensor fusion greenhouse patrol robot tracking method, first author

UWB-based following robot

Greenhouse inspection robot cluster
The inspection vehicle will record the diseased plants according to the camera information, and send it to the spraying vehicle, which will automatically arrive at the recorded location.

Acousto-optic positioning hexapod disaster relief
The hexapod robot turns in the direction of the sound source after hearing the target sound, and tracks the light source after recognizing the target light source.
🎖 Selected Honors and Awards
- National Scholarship (国家奖学金)
- Provincial-Level Merit Student of Jiangsu Province (江苏省三好学生)
- Outstanding Graduates of Jiangsu Province (江苏省优秀毕业生)
- Principal Scholarship (校长奖学金)
- National Student Electronic Design Competition - National First Prize(Top 1.8%, total 17,313 teams)
- “Huawei Cup” The 18th China Post-Graduate Mathematical Contest - National Second Prize
- Artificial Intelligence and Robotics Innovation Competition - National Grand Prize
📖 Educations
- PhD in Embodied AI, University of Hong Kong.
- M.S in Electronic Information (School of Automation), Southeast University.
- B.S in Electronic Information Engineering, Jiangsu University, Rank 1/111.